Ubuntu Linux (3) - 서버 구축(운영) 시 필요한 필수 개념, 하드 디스크 관리, RAID, LVM
2024-09-13(FRI)
01. 전일 내용 - 서버 구축 시 알아야 되는 필수 개념, 명령어
01-1. 시스템의 시작과 종료
(1) 시작 커맨드
init 6 (재부팅 커맨드, Run-Level)
(2) 종료 커맨드
shutdown -P now
poweroff
halt -p
init 0(Run-Level)
(3) 종료 작업의 경우 다른 사용자들이 접속을 전부 종료한 상태에서 시스템을 종료한다.
(4) 예약된 shutdown 작업을 취소 : shutdown -c
(5) 터미널 종료 : exit
(6) 로그아웃 : logout
01-2. 런 레벨
(1) 0~6레벨까지 런 레벨이 존재한다.
- 런레벨은 시스템의 운영 상태나 모드의 설정을 정의하는 개념으로, 시스템의 부팅 및 종료 과정에서 어떤 서비스를 시작하고 어떤 서비스를 중지할지 결정한다.
(2) 0 : Power off
(3) 1 : Rescue
- 시스템 복구 모드로 루트 관리자만 접근 가능하다.
(4) 2 : Multi User Mode
- 사용하지 않는 레벨 모드
(5) 3 : Multi User Mode
- Text Mode
(6) 4 : Multi User Mode
- 사용하지 않는 레벨 모드
(7) 5 : Graphical Mode
- GUI(Graphic User Interface)를 사용하는 모드
(8) 6 : Reboot
(9) ls -l runlevel*.target : 현재 디렉토리에서 이름이 runlevel*.target 형식과 일치하는 파일들을 상세히 나열
(10) default.target 파일에 Run-Level이 연결되어 있다.
(11) default.target 확인 커맨드 : ls -l /lib/systemd/system/default.target
(12) run-level을 제어 : CLI 환경으로 부팅
> ln -sf /lib/systemd/system/multi-user.target /lib/systemd/system/default/.target
> startx (기본적인 GUI 환경을 우선적으로 보여준다 이후 터미널로 접속한다.)
> 다시 GUI 환경으로 부팅 :
→ ln -sf /lib/systemd/system/graphical.target /lib/systemd/system/default/.target
01-3. vi Editor
(1) 현업에서 많이 사용되는 에디터 유닉스, 리눅스 운영체제에서 모두 지원하고 있다.
(2) 일반적인 vi 에디터 작업 흐름
vi [파일명] > 파일 실행 시 초기 명령 모드 → 입력 모드로 전환(:a 또는 :i) → 내용 작성 → 입력 모드에서 빠져나오기(ESC) → 이후 종료(:q), 저장 후 종료(:wq), 작업 취소(:q!)
01-4. CD/DVD Mount
(1) 마운트 작업 : 하드 디스크, CD-ROM 사용 시 리눅스에서는 해당 장치들을 파일 시스템의 특정 디렉토리에 연결해서 사용할 수 있도록 준비하는 작업을 의미한다.
(2) cat /dev/cdrom, /dev/sr0으로 마운트 내역 확인
(3) df -k(파일 시스템의 상태, 여유 공간 등 표시) 또는 mount( 현재 시스템에 마운트된 파일 시스템의 정보를 표시)
(4) mkdir /cd-device
(5) mount /dev/cdrom /cd-device
(6) cd cd/device
(7) 마운트 커맨드는 shutdown하게 되면 마운트가 해제되므로 다른 경로에 저장해 둬야 영구적으로 마운트 데이터들이 저장된다.
(8) 마운트 해제 시 : umount 사용
- umount 명령에서 "device busy" 문구가 노출된다면 해당 파일 시스템이 현재 사용 중이거나 파일 시스템에 직접적으로 접근(경로에 들어와 있는 상태)이므로 사용을 하지 않거나 다른 경로로 이동한 뒤 umount 커맨드를 수행한다.
01-5. 기본 커맨드
(1) ls, cd, pwd, rm, cp, touch, mv, mkdir, rmdir, cat, more, head, tail, less, file, clear
01-6. 사용자 및 그룹 관리 커맨드
※ 사용자 및 그룹 정보와 연관된 디렉터리
(1) /etc/passwd : 사용자의 계정 정보를 관리한다.
(2) /etc/shadow : 계정의 암호 및 암호 정보를 저장한다.
(3) /etc/group : 그룹의 정보들을 저장하고 있다.
(4) /etc/gshadow : 그룹의 암호, 암호 정보를 저장한다.
※ 관련 커맨드들
(5) adduser, passwd, usermod, userdel, change, groups, groupadd, groupmod, groupdel, gpasswd
01-6. 파일 및 디렉터리 소유권, 허가권
(1) 허가권(Permissions) : 파일이나 디렉터리에 대한 접근 및 작업 권한을 나타내는 개념이다.
- 허가권 영역은 소유자, 소유자의 그룹, 그 외 사용자들로 구분된다.
- 허가권의 접근 및 작업 권한은 Read(r), Write(w) , Execute(x) 3가지가 있다.
- r : 4, w : 2, x : 1로 구분하여 허가권의 경우 숫자로도 표현 가능하다.
- 파일이나 디렉터리의 권한(허가권)을 변경하는 직접적인 커맨드는 chmod이다.
(2) 소유권(Ownership) : 파일이나 디렉터리를 소유한 사용자나 그룹을 정의하는 개념이다.
- 파일이나 디렉터리의 소유자 및 그룹을 변경하는 데 사용되는 커맨드는 chown이다.
- chown [사용자명] .[그룹명] [파일 이름.확장자]
01-7. 링크(Link)
(1) 링크
- 파일 시스템에서 사용되는 개념으로 파일이나 디렉터리의 참조를 생성하는 방법이다.
- 파일은 inode Block + Data Block으로 구성된다.
(1) 하드 링크(Hard Link)
- 하드 링크는 원본 파일과 동일한 inode를 직접적으로 가리킨다. (동일한 inode 정보를 갖고 있는 링크 형태)
- 디렉터리 링크는 생성이 불가능하다.
- 원본 파일이 소실되더라도 해당 데이터에 접근 가능하다.
(2) 심볼릭 링크(Symbolic Link)
- 심볼릭 링크는 원본 파일에 대해 간접적인 포인터(이름을 가리키는)를 생성하는 링크다. (하드 링크와 달리 원본 파일과 다른 inode 번호를 갖는다.)
- 하드 링크와 달리 디렉터리 링크도 생성 가능하다.
- 원본 파일, 디렉터리가 소실되면 해당 데이터에 접근 불가능하다.
(원본 파일의 경로를 간접적으로 참고하고 있기 때문에 원본 파일이 이동하거나 이동, 이름이 변경되면 링크가 깨지게 된다.)
(3) 관련 커맨드 : ln
ln -s basefile softlink
> 생성된 링크를 확인
ls -il (i의 경우 inode까지 표시해 준다.)
01-8. 프로그램(패키지) 설치 매니저 : dpkg, apt(apt-get)
(1) dpkg
- Windows의 setup.exe와 동일하게 동작하는 패키지 매니저
- 대표적인 단점으로는, 패키지와 연관된 의존성들을 관리해줄 수 없다.(함께 설치해 주지 않는다.)
(2) apt(apt-get)
- dpkg를 발전시킨 패키지 매니저로 dpkg의 단점이였던 의존성 문제를 해결했다.
(3) /etc/apt/sources.list
- apt 패키지 매니저가 패키지들을 다운로드하고 업데이트하는 Repository의 URL 접속 주소를 갖고 있다.
(4) apt update
- 해당 커맨드를 통해 패키지 목록을 업데이트할 수 있다.
(5) apt remove
- 연관된 패키지를 제거한다.
(6) apt purge
- 패키지와 관련 설정된 파일을 포함해 모두 제거한다.
(7) apt autoremove
- 사용하지 않는 패키지를 제거한다.
(8) apt-cache show
- 특정 패키지의 상세 정보를 출력한다.
(9) apt-cache depends
- 특정 패키지와 연관된 의존성 정보들을 출력한다.
01-9. 파일 압축
(1) 리눅스에서 가장 많이 사용하는 압축 확장자는 xz, bz2 등이 있다.
(2) 파일 묶기 (.tar 사용)
- tar cvf my.tar /etc/systemd/
> tar 명령어를 사용하여 /etc/systemd/ 디렉토리의 내용을 my.tar라는 파일로 압축하게 된다.
(3) tar cvfJ my.tar.xz /etc/systemd
- /etc/systemd 디렉토리의 내용을 my.tar.xz라는 이름의 압축된 아카이브 파일로 생성하게 된다.
(1) 리눅스 운영체제의 시작과 종료 방법, 가상 콘솔, 런레벨
(2) vi Editor 사용법
(3) CD/DVD/USB 마운트 및 사용법
(4) 필수 기본 커맨드
(5) 사용자 및 그룹 관리
(6) 파일 및 디렉터리 / 소유권 / 허가권
(7) 리눅스용 프로그램 설치를 위한 커맨드 : dpkg, apt-get
(8) 네트워크 설정, 프로세스, 서비스, 데몬
(9) GRUB 부트로더 이해, 커널 컴파일 실습
(10) 하드 디스크 1개 추가, RAID Level 0, 1, 5
(11) LVM
1. 서버 구축 시 알아야 할 개념 : 파일 위치 검색
1-1. 개요
(1) 리눅스에서 특정 파일의 위치를 검색하는 커맨드가 존재한다.
(2) 가장 많이 사용되는 커맨드는 find이다.
1-2. find /etc -name "*.conf"
(1) /etc 디렉터리 하위 디렉터리에서 확장자가 *.conf인 파일을 검색한다.
1-3. find /home -user ubuntu
(1) /home 디렉터리 하위에서 소유자가 ubuntu인 파일을 검색한다.
1-4. find ~ -perm 644
(1) 현재 사용자의 홈 디렉터리 하위에서 허가권이 644인 파일을 검색한다.
1-5. find /usr/bin -size +10k -size -100k
(1) /usr/bin 디렉터리 하위 디렉터리에서 파일 크기가 10~100KB인 파일을 검색한다.
1-6. find ~ -size 0k -exec ls -l {} \;
(1) 현재 사용자 홈 디렉터리 하위 디렉터리에서 파일 크기가 0인 파일의 목록을 상세 출력한다.
1-7. find /home -name "*.swp" -exec rm {} \;

(1) /home 디렉터리 하위 디렉터리에서 확장자가 *.swp인 파일을 검색한다.
2. 서버 구축 시 알아야 할 개념 : 시스템 설정
2-1. 네트워크 설정
(1) nmtui 커맨드를 사용해서 직접 제어할 수 있다.
2-2. 방화벽 설정
(1) 방화벽 설정의 경우 ufw 커맨드를 사용하며 처음 우분투를 설치하면 작동하지 않으므로 ufw enable 커맨드로 켜주는 것이 좋다.
(2) 기본적으로 ufw enable를 수행시키면 외부에서 접속하는 모든 포트가 닫힌다. 따라서 외부에 서비스를 제공할 목적이라면 필요한 포트는 열어주는 방식으로 운영하는 것이 좋다.
3. 서버 구축 시 알아야 할 개념 : cron & at
3-1. cron

(1) 주기적으로 반복되는 작업을 자동화할 수 있도록 시스템 작업을 예약하는 커맨드가 cron이다.
(2) cron과 관련된 데몬은 crond이고, 관련 파일은 /etc/crond이다.
(3) /etc/crontab의 형식 : 분 시 일 월 요일 사용자 실행 명령
(4) Ex) 00 05 1 * * root cp -r /home /backup
(5) /etc/crontab 파일이 시간별, 일별, 주별, 월별로 호출하는 디렉터리 목록의 예시
> 01 * * * * root run-parts /etc/cron.hourly
> 02 4 * * * root run-parts /etc/cron.daily
> 03 4 * * 0 root run-parts /etc/cron.weekly
> 42 4 1 * * root run-parts /etc/cron.monthly
3-2. at
(1) cron은 주기적으로 반복되는 작업을 예약하지만 at은 일회성 작업을 예약하는 커맨드다. 예약해 두면 한 번만 실행되고 소멸된다.
(2) at 3:00AM tommorow
- 내일 새벽 3시
(3) at 11:00pm January 30
- 1월 30일 오후 11시
(4) at now + 1 hours
- 1시간 후
4. 서버 구축 시 알아야 할 개념 : 네트워크 관련 설정
4-1. TCP(Transmission Control Protocol) / IP(Internet Protocol)
(1) TCP/IP
- 컴퓨터끼리 네트워크를 통해 통신하는 주요 규약을 프로토콜이라고 정의한다. 그중 가장 널리 사용되는 프로토콜 중 하나다.
(2) 통신의 전송/수신을 다루는 TCP/IP 프로토콜로 구성된다.
4-2. 호스트명 & 도메인명
(1) 호스트 이름은 각 컴퓨터(디바이스)에 지정된 이름을 의미한다.
(2) 도메인 이름은 도메인 이름은 인터넷에서 특정 웹 사이트나 서버를 식별하는 텍스트 형식의 주소를 말한다.
(3) 예를 들어 호스트명이 this, 도메인명이 hello.co.kr이라면 전체 이름은 host.hello.co.kr이 된다
4-3. DNS 서버 주소
(1) DNS 서버 주소 관련해서 설정 파일은 /etc/resolv.conf 파일이며 내부에 nameserver DNS 서버 IP 형식으로 기재되어 있다.
(2) 가상 머신을 사용하면 하이퍼바이저가 DHCP 서버, 게이트웨이, DNS 서버 역할을 모두 가상화해서 제공한다.
4-4. 일반적인 네트워크 설정 주요 커맨드
(1) nm-connection-editor & nmtui
- nm-connection-editor와 nmtui는 모두 NetworkManager를 사용하는 시스템에서 네트워크 연결 설정 및 구성 정보를 GUI 환경에서 수정할 수 있도록 돕는 도구다.
(2) systemctl start/stop/restart/status [서비스명]
- systemctl은 systemd 시스템 및 서비스 관리자에서 서비스와 시스템 상태를 관리하는 명령어를 의미한다.
(3) ifconfig [장치 이름]
- 네트워크 인터페이스의 설정 및 상태를 확인하는 데 사용되는 명령어를 의미한다.
(4) nslookup
- nslookup은 DNS(도메인 네임 시스템) 쿼리를 수행하는 명령어를 의미한다.
4-5. 네트워크 설정 파일들 확인
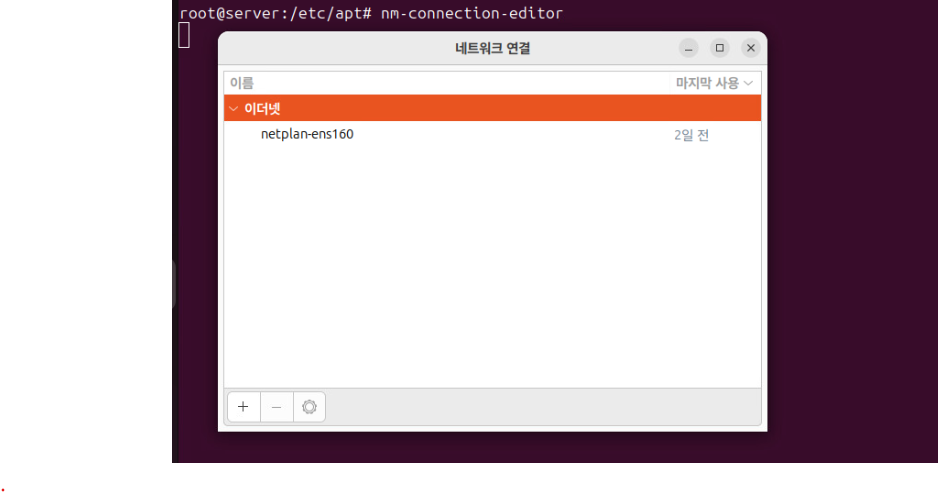
(1) nm-connection-editor를 통해 네트워크 인터페이스 설정 화면으로 접속해 GUI 환경에서 작업할 수 있다.
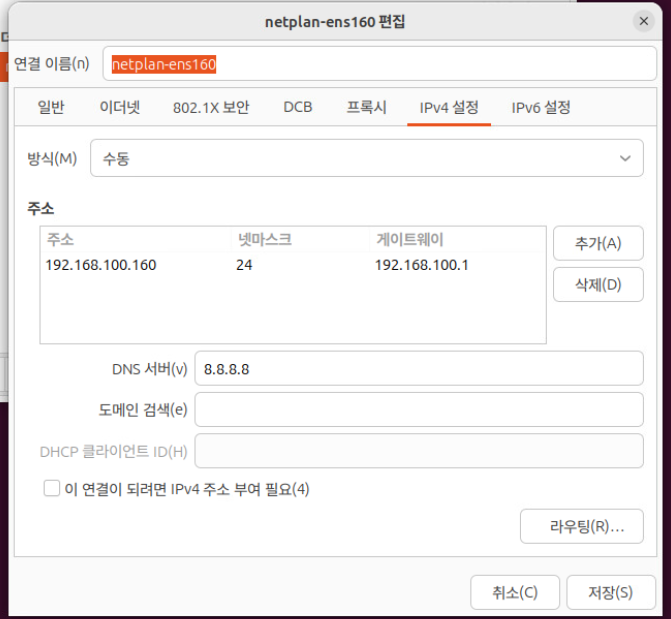
(2) 위와 같이 인터페이스를 선택하고 관련된 설정 정보를 적용하거나 수정할 수 있다.

(3) nmtui 커맨드로 네트워크 인터페이스에 대해 설정 및 수정을 진행할 수 있다.

(4) ifdown 명령이 수행되지 않는다면 apt를 통해 관련 패키지를 설치한다.


(5) /etc에서 nano resolv.conf 커맨드를 수행해 본다.

(6) /etc/netplan 경로로 접속한다.


(6) DHCP 설정 정보가 들어가 있다.




(7) 위의 경로로 접속한다.
(8) 버전이 바뀌면서 system-connections에 들어 있던 설정 파일이 /etc/netplan에 존재하는 것을 알 수 있었다.
5. 서버 구축 시 알아야 할 개념 : Pipe Operation, Filter, Redirection
5-1. Pipe operation
(1) 두 개의 커맨드를 연결하는 통로 역할을 수행하는 연산자다.
(2) command1 | command2
5-2. Filter
(1) 필요한 부분만 따로 필터링해 주는 커맨드로 보면 된다.
(2) 대표적으로 grep, tail, wc, sort, awk, sed 등의 커맨드가 존재한다.
(3) 주로 파이프 연산자와 함께 사용되는 커맨드다.
(4) ps -ef | grep bash

(5) ps -ef 명령을 입력하면 모든 프로세스 번호를 출력하기 때문에 bash라는 키워드가 포함된 프로세스만 출력하게 된다.
5-3. Redirection
(1) 리디렉션은 표준 입출력의 방향을 수정해 준다.
(2) 표준 입력은 키보드, 출력은 모니터이지만 이 부분을 파일로 처리할 때 주로 사용한다.
(3) ls -l > list.txt
ls -l 결과를 화면에 출력하지 않고 list.txt 파일에 기록한다. 만약 존재하는 파일이라면 해당 파일에 덮어쓴다.
(4) ls -l >> list.txt
(3)번과 동일한 커맨드이지만 list.txt 파일이 기존에 존재한다면 기존 내용에 이어서 쓰게 된다.
(5) sort < list.txt
list.txt 파일을 정렬해서 화면에 출력한다.
(6) sort < list.txt > out.txt
list.txt 파일을 정렬해서 out.txt 파일에 쓴다.
6. 서버 구축 시 알아야 할 개념 : Process, Daemon, Service
6-1. 프로세스(Process)
(1) 프로세스는 디스크에 저장된 프로그램들이 실제 메모리 영역에 적재되어 실행 가능한 상태를 프로세스라고 정의하고 있다.
6-2. Foreground Process
(1) 실제 사용자와 상호 작용하는 프로세스를 말한다.
6-3. Background Process
(1) 실행 중이지만 실제 사용자한테 보여지지 않고 뒷단에서 서비스 유지 및 작업을 위해 실행되는 프로세스를 말한다.
(2) 백신, 서버 데몬 등이 백그라운드 프로세스에 포함된다.
6-4. Process Number
(1) 메모리에 로드되어 활성화된 프로세스를 구분하기 위한 식별자로 볼 수 있다.
(2) 각 프로세스에 할당된 고유 번호(식별자)를 Process number라고 한다.
6-5. 작업 번호
(1) 백그라운드 프로세스의 순차적인 식별자(번호)를 의미한다.
6-6. 부모 프로세스(Parent Process)와 자식 프로세스(Child Process)
(1) 모든 프로세스는 독립적으로 실행되는 것이 아니라 부모 프로세스의 하위 프로세스로 종속되어 실행된다.
(2) 예를 들어 웹 브라우저인 Firefox는 X Winodw가 실행 중인 상태에서 실행될 수 있기 때문에 X Window가 부모 프로세스Firefox는 X Window 프로세스의 자식 프로세스가 된다.
6-7. 프로세스 처리 명령어
(1) ps -ef
- 현재 시스템에서 실행 중인 모든 프로세스의 정보를 출력한다.
(2) kill
- 프로세스를 종료할 때 사용된다.
(3) pstree
- 실행 중인 프로세스의 계층 구조를 트리 형태로 출력한다.
6-8. 프로세스 명령어 실습 : ps -ef

(1) ps -ef를 실행하면 실행 중인 프로세스들이 출력된다.
(2) UID(User ID)
- 프로세스를 실행한 사용자의 ID
(3) PID(Process ID)
- 실행 중인 프로세스 자체에 대한 ID, 각 프로세스는 고유한 ID를 갖는다.
(4) PPID(Parent PID)
- 실행 중인 프로세스의 부모 프로세스 ID, 프로세스가 생성된 부모 프로세스의 PID를 의미한다.
(5) C
- 프로세스의 CPU 사용 우선순위를 나타내는 지표, 프로세스가 CPU를 점유하고 사용하는 데 있어 상대적인 우선 순위를 나타낸다. 참고로 0 값은 기본 우선순위 값이다.
(6) STIME
- 프로세스가 시작된 날짜 및 시간
(7) TTY
- 프로세스가 연결된 터미널을 장치를 보여준다.
(8) TIME
- 프로세스가 사용한 CPU 시간의 총합을 나타낸다.
(9) CMD
- 프로세스를 실행하고 있는 명령어와 해당 인수를 표시한다.
6-9. 프로세스 명령어 실습 II

(1) ps -ef | grep nmtui
- 시스템에서 실행 중인 프로세스 정보를 상세하게 나열하고 해당 출력값을 파이프 연산자를 통해 넘긴다.
- 넘겨받은 출력값에서 nmtui라는 문자열이 포함된 줄만 따로 필터링해서 보여주게 된다.

(2) ps -ef | grep 24789
- 시스템에서 현재 실행 중인 프로세스 중 PID 값이 24789인 프로세스 목록을 상세하게 출력한다.
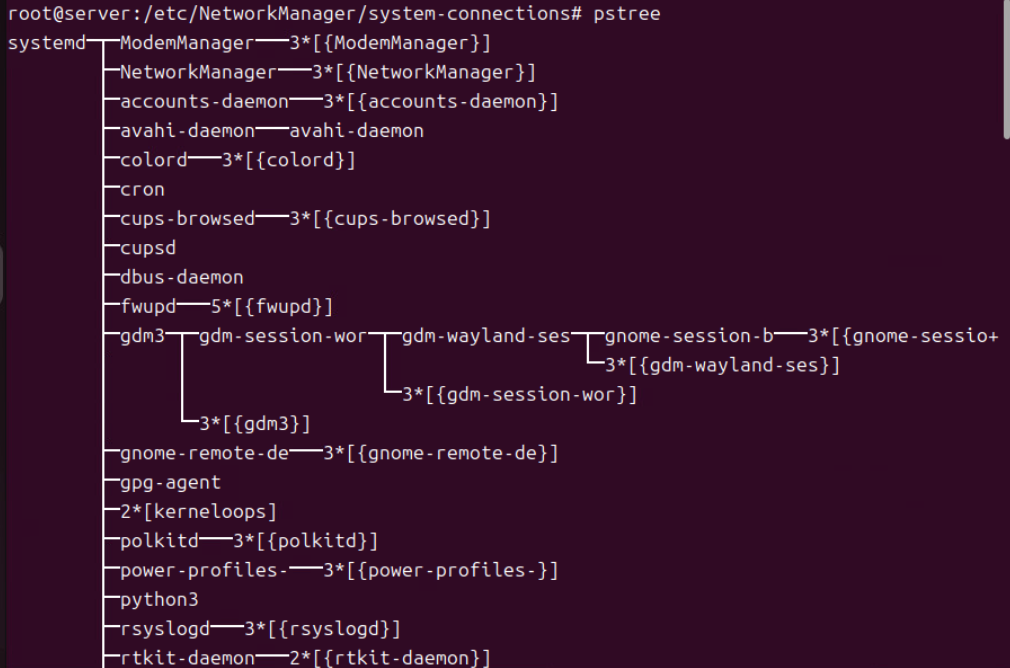
(3) pstree
- 시스템에서 현재 실행 중인 프로세스 리스트들을 계층 구조 형식으로 출력한다.

(4) kill -9 24789
- 현재 실행 중인 프로세스 중에서 PID가 24789인 프로세스를 강제 종료한다.

(5) 해당 kill 커맨드로 인해 실행 중이던 프로세스가 강제 종료된 것을 확인할 수 있다.

(6) yes > /dev/null
- 기본적으로 "y"를 지속해서 출력한다. > /dev/null 명령으로 이전 값의 출력값이 /dev/null로 이동되어 실제 화면에 표시되지 않는다.

(7) ps -ef | grep yes
- 위와 동일하게 시스템에서 현재 실행 중인 프로세스 목록을 상세하게 출력하면서, yes라는 문자열이 포함된 라인만 따로 필터링해서 출력하게 된다.

(8) 위의 그림은 yes > /dev/null로 실행시킨 프로세스의 PID를 확인하고 다른 터미널을 열어서 해당 PID를 가진 프로세스를 강제 종료함에 따라 yes > /dev/null로 실행 중이던 프로세스가 죽은 상황이다.
6-9. 서비스(Service)
(1) 데몬이라고도 불리는 서비스는 서버 사이드의 프로세스를 말한다.
(2) 서비스는 웹 서버, DNS 서버, 데이터베이스 서버 등의 프로세스를 의미한다.
- 웹 서버 데몬, 데이터베이스 서버 데몬 등으로 불리기도 한다.
(3) 서비스는 시스템에서 동작 중인 프로세스이므로 백그라운드 프로세스에 해당된다.
(4) 실행 및 종료는 systemctl start/stop/restart [서비스 이름]으로 사용된다.
- Ex) systemctl start httpd (웹 서버 시작)
6-10. 서비스와 소켓(Service & Socket)
(1) 서비스는 평상시에도 가동되는 서버 프로세스이며 소켓은 필요할 때만 작동하는 서버측 프로세스라고 볼 수 있다.
(2) 서비스 소켓은 systemd 서비스 매니저 프로그램으로 동작시키거나 관리한다.
(3) systemctl(System Control)
- 서비스 시작/중지/재시작 : systemctl start/stop/restart ~
- 서비스 상태 확인 : systemctl status ~
- 서비스 사용/사용 안 함 : systemctl enable/disable ~
(4) 서비스는 항상 가동되지만 소켓은 외부에서 특정 서비스를 요청할 경우 systemd가 구동시키고 요청이 종료되면 소켓도 종료된다.
(5) systemd가 서비스 구성 시 시간이 다소 소요되므로 소켓 실행까지 시간이 좀 걸릴 수 있다.
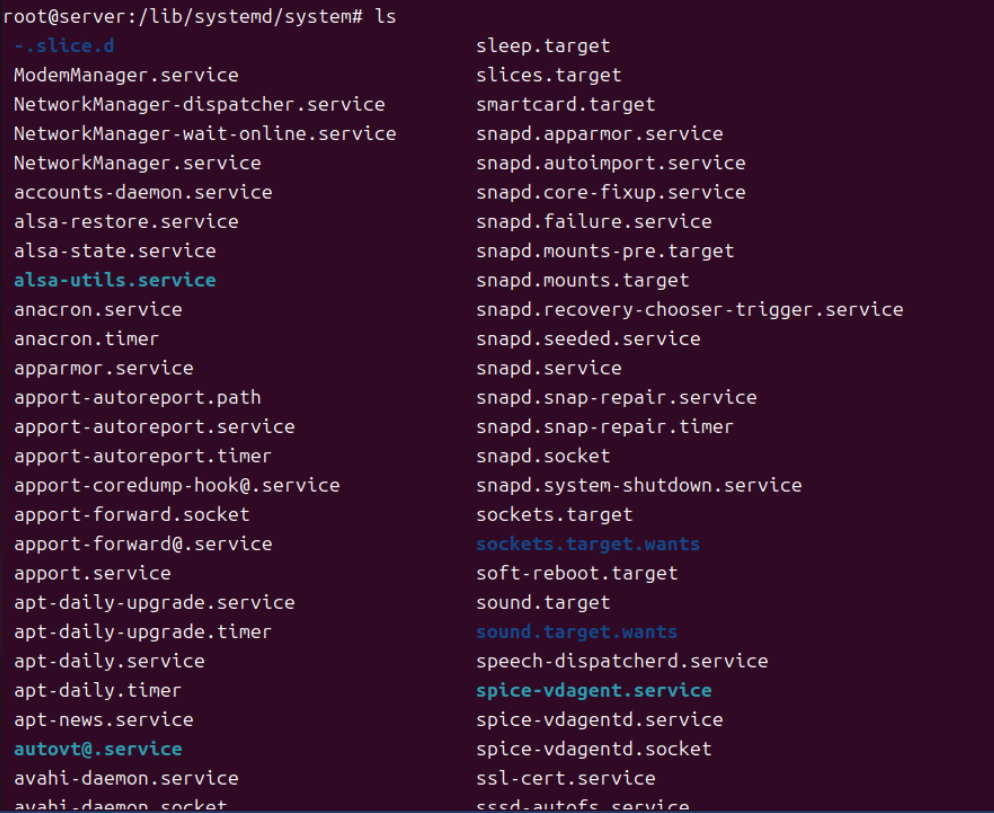
(6) /lib/systemd/system 디렉터리의 경우 시스템의 systemd 서비스 유닛 파일이 저장되는 디렉터리다. 시스템 서비스와 관련된 파일들을 포함하고 있고, systemd 커맨드에 의해 실행되고 종료된다. ls로 관련 서비스 유닛들을 확인하고 있다.
6-11. 서비스(Service - Daemon) 실습(apache2 service)

(1) 웹 서비스 실습을 위해 apt -y install apache2 명령으로 웹 서버 관련 패키지를 설치한다.
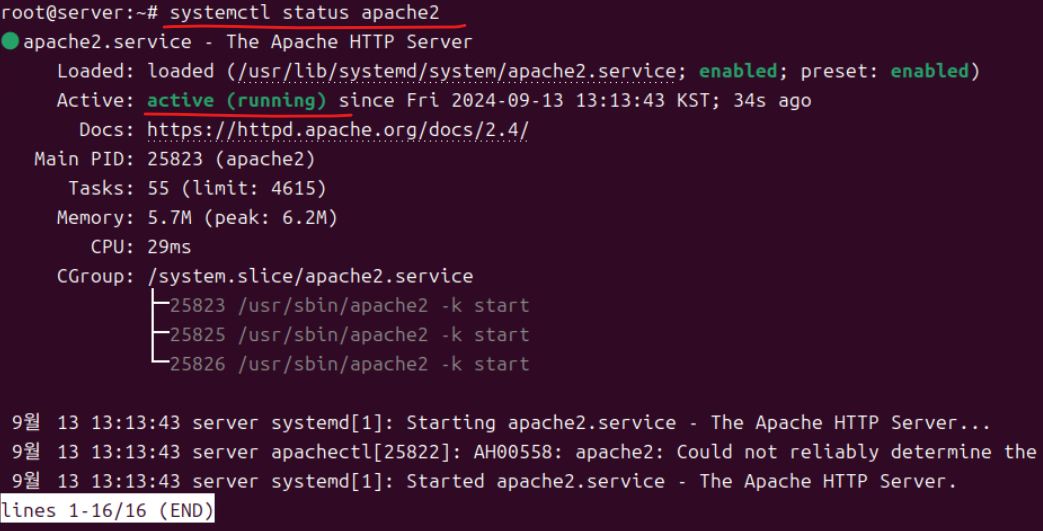
(2) systemctl status apache2로 apache2 서비스를 시작한다.
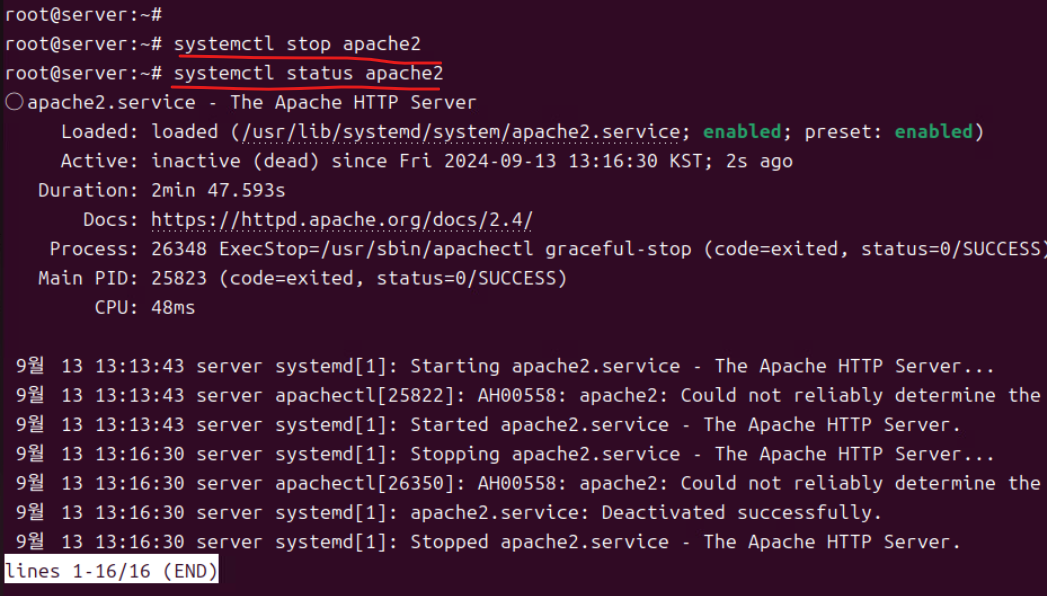
(3) systemctl stop 커맨드로 관련 서비스를 중지시킬 수 있으며 실행하면 inactive 상태로 변경된 것을 확인할 수 있다.
※ 해당 챕터에서는 하드 디스크를 추가하는 방법, 하드 디스크를 여러 개를 하나처럼 운영할 수 있는 서비스를 RAID라고 하는데 RAID 및 LVM에 대해 알아본다.
※ 사용자별로 사용량을 제한하는 Quota에 대한 개념
- SATA, SCSI에 대한 이해
- 하나의 디스크를 추가하는 방법
- 다양한 RAID 작동 방식 이해
- 여러 개의 디스크를 장착하여 RAID 구현 실습
- RAID 고장 & 원상 복구 방식 실습
- LVM에 대한 이해와 실습
- Quota에 대한 이해와 실습
7. SATA(Serial ATA), SCSI(Small Computer System Interface) & 하드 디스크 1개 추가
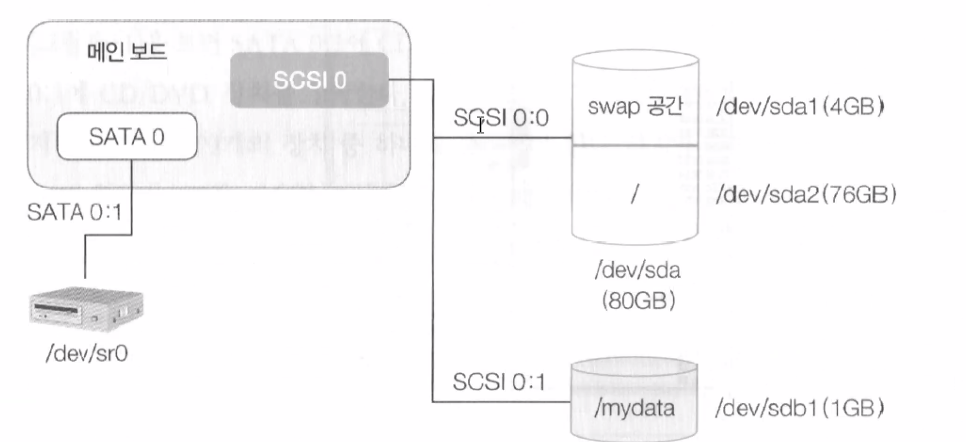
7-1. SATA 장치와 SCSI 장치 구성

(1) 위의 구성은 메인보드의 SATA 0 슬롯에 각각 30개의 SATA 장치를 장착할 수 있다.
(2) SATA (Serial ATA)와 SCSI (Small Computer System Interface)는 컴퓨터에서 저장 장치와 다른 주변 기기들을 연결하고 통신하는 데 사용되는 인터페이스를 말한다.
(3) SATA는 최신 저장 장치에서 널리 사용되는 인터페이스다. 주로 하드 디스크 드라이브(HDD)와 솔리드 스테이트 드라이브(SSD)를 연결하는데 사용된다.
(4) SCSI는 주로 서버나 고성능 워크스테이션에서 사용되는 인터페이스로, 저장 장치와 기타 주변 기기들을 연결하는 데 사용된다.
7-2. 하드 디스크 추가
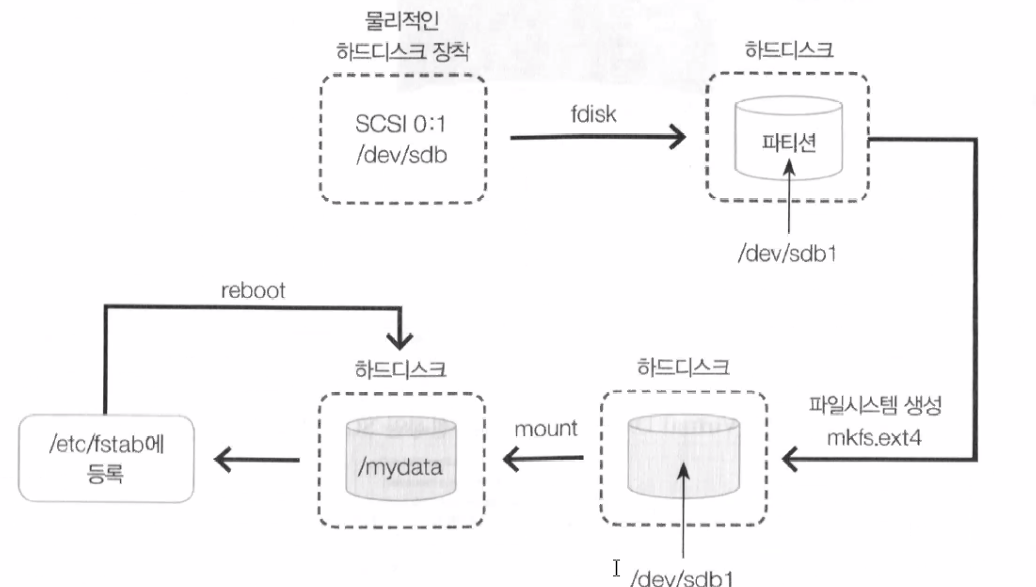
(2) 리눅스에서는 하드 디스크 파티션을 그냥 사용할 수 없고 특정 디렉터리에 마운트시켜야 사용 가능하다.
(3) 실습상에서는 특정 디렉터리를 만들고 해당 디렉터리에 마운트한다.
(4) /etc/fstab
- /etc/fstab은 Linux 및 Unix 계열 운영체제에서 파일 시스템과 장치의 자동 마운트 설정을 정의하는 구성 파일이며 시스템 부팅 시 자동으로 파일 시스템을 마운트하거나 해제하는 방법을 지정한다.
7-3. 하드 디스크 1개 장착 실습 / 재부팅 이후에도 마운트가 유지되도록 설정

(1) ESXi에서 하나의 디스크를 추가한다.
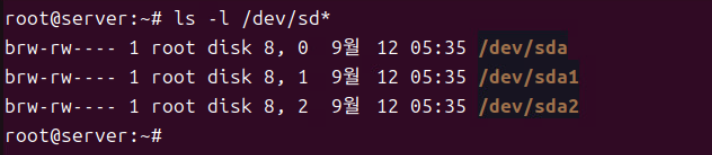
(2) 위와 같이 하드 디스크 추가 후 가상 머신에서 바로 반영되지 않을 수 있으니 reboot한다.
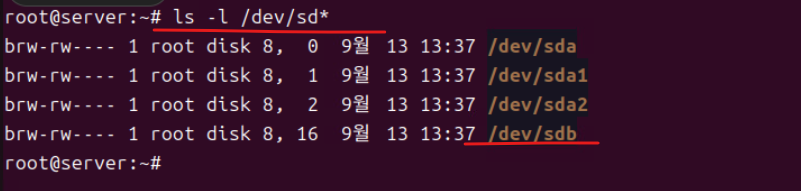
(3) 재부팅 후 확인된다.
- 현재 보이는 경로는 /dev/sda ... /dev/sdb가 표시되는데 /dev는 리눅스 시스템에서 장치 파일과 관련된 정보를 저장하는 디렉터리다. 해당 디렉터리 내의 파일들은 실제 물리 하드웨어 장치와 연결되어 있다.
- 해당 경로에 대한 특정 파티션 영역을 나타낸다.

(4) 파티션 작업을 위해 fdisk /dev/sdb로 파티션 매니저에 접속한다.
(5) 아직 파티션 작업 전이지만 위에서 보이는 것처럼 파티션 작업 후 반드시 저장 / 종료를 한다.

(6) 파티션 생성을 위해 n을 입력한다.

(7) p 옵션을 줘서 파티션을 생성한다.
- First sector에서 바로 엔터를 쳐서 2048로 적용
- Last sector 부분도 엔터를 쳐서 기본값 209751로 적용한다.
- 1GB 용량의 1개의 파티션이 생성되었다.
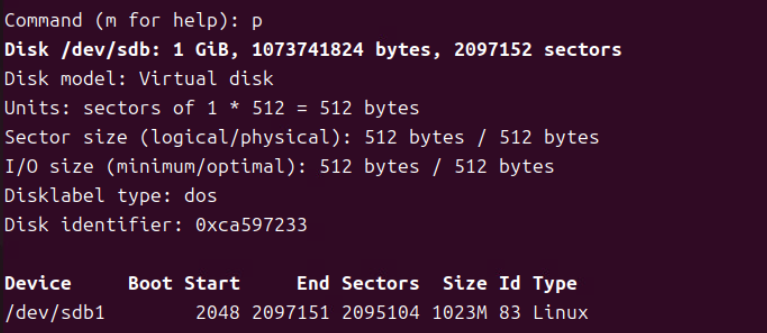
(8) 이후 생성된 파티션은 p 옵션으로 확인한다.
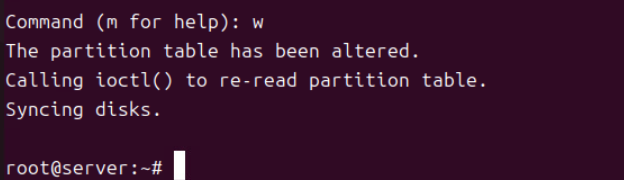
(9) 지금까지 작업한 부분을 저장한 뒤 파티션 매니저를 종료하기 위해 w 옵션을 준다.

(10) 방금 작업한 파티션 영역이 확인된다.
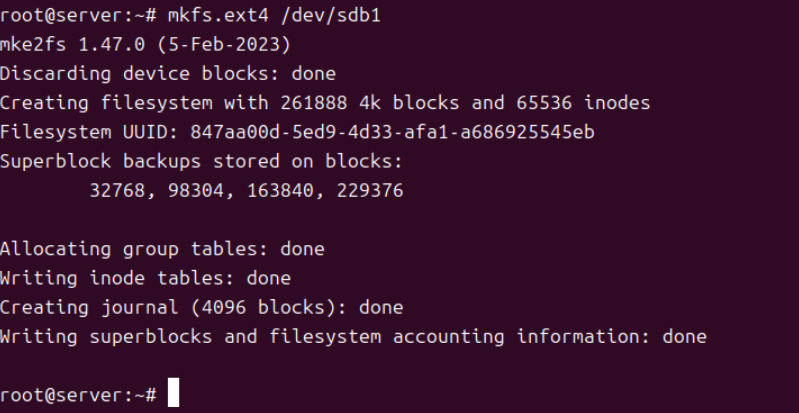
(11) mkfs.ext4 /dev/sdb1 커맨드의 경우 방금 생성한 파티션에 대해서 파일 시스템을 ext4로 적용시킨 커맨드다.
(12) 현재까지의 작업을 기준으로 마지막으로 마운트를 적용시켜서 해당 디스크를 리눅스 환경에서도 사용할 수 있도록 작업해야 한다.
(13) 이후 /mydata 디렉터리를 새로 생성하고 해당 디렉터리에 마운트를 진행한다.

(14) cp /boot/vmlinuz-6.8.0-* .
- 파일을 복사하는 cp 명령어를 사용하여 /boot 디렉토리 내의 특정 파일을 현재 작업 디렉토리로 복사하는 작업을 수행한다.
- vmlinuz는 "Virtual Memory LINUx gZip-compressed"의 약자로, 리눅스 커널의 압축된 실행 파일을 의미한다.
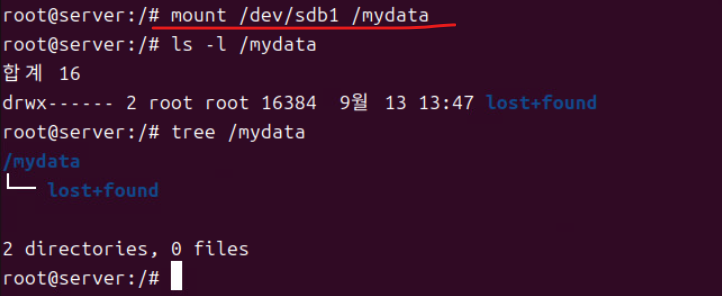
(15) /mydata를 마운트하는 작업을 수행한다
> mount /dev/sdb1 /mydata
> mount [마운트할 장치 또는 파티션 디렉터리 경로] [마운트 위치]

(16) 위의 과정에서 mount /dev/sdb1 /mydata 커맨드로 마운트를 해줬기 때문에 df -k 커맨드로 확인해 보면 마운트된 파일 시스템들을 확인한다.
(17) 과정
- 하드 디스크 추가 > 파티셔닝 작업 > 파일 시스템 작업 > 디렉토리 생성 > 마운트 작업 진행 > df -k로 내역 확인

(18) 이후 작업에 실패하거나 편집기에서 설정값을 잘못 건드려서 부팅이 되지 않을 경우를 대비해서 복원을 위해 지금까지의 과정을 snapshot을 저장해 둔다.

(19) vi 편집기나 geditor로 /etc/fstab의 편집기를 연다.
* /etc/fstab
- 해당 설정 파일은 리눅스에서 파일 시스템의 자동 마운트에 대한 설정이 정의되어 있는 파일이다.
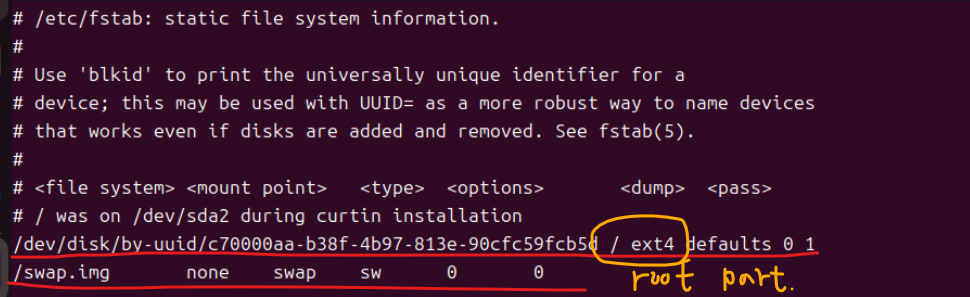
(20) 해당 부분이 루트 파티션에 대한 스왑 기록이 남아 있는 부분이다.
- 해당 파일의 구조

<파일 시스템> <마운트 지점> <파일 시스템 유형> <옵션> <덤프> <패스>
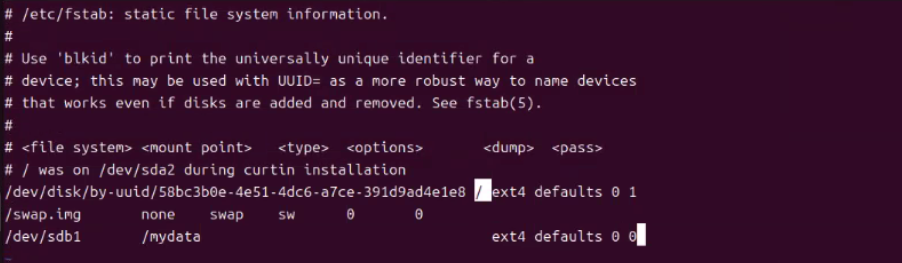
(21) 편집기로 /dev/sdb1 : 파일 시스템 경로, /mydata : 마운트 경로, ext4 : 파일 시스템 유형, defaults 0 0을 입력해 준다.
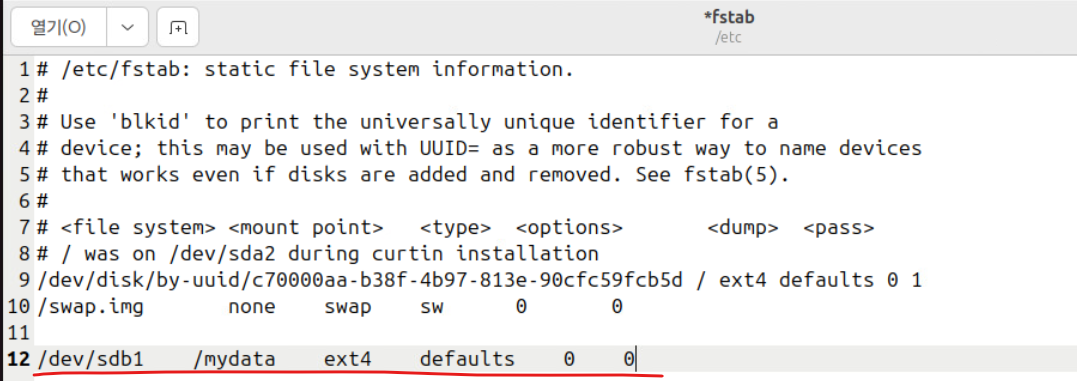
(22) 위와 같이 geditor를 써도 무방하다.
- 마운트 작업 이후 재부팅 이후에도 마운트된 디스크가 유지되도록 하기 위해 위와 같은 작업을 수행해 주는 목적이다.
- 파일을 저장했다면 저장하고 편집기를 빠져 나와서 reboot(재부팅)을 진행한다.
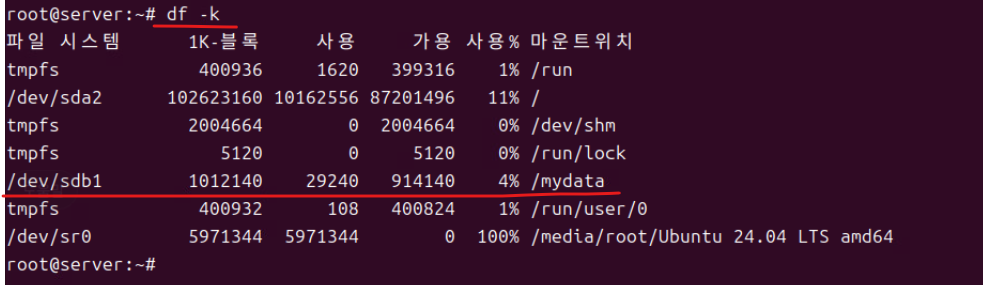
(23) 재부팅 이후 df -k로 마운트 디스크를 확인한다.
* df -k : 파일 시스템 & 디스크 사용량 및 기타 정보를 출력하는 커맨드
8. RAID (Redundant Array of Inexpensive/Independent Disks)
8-1. RAID의 정의와 개념
(1) 서버 컴퓨터의 저장 장치 대부분은 하드웨어 RAID(Redundant Array of Inexpensive/Independent Disks) 또는 소프트웨어 RAID 방식을 사용한다.
(2) 우선 RAID란 여러 개의 디스크를 하나의 하드 디스크처럼 사용하는 방식이다. 비용을 줄이면서도 신뢰성을 높일 수 있으며 성능 향상을 기대해 볼 수 있다.
8-2. Hardware(H/W) RAID

(1) 하드웨어 제조업체에서 여러 개의 하드디스크를 연결한 장비를 따로 만들어서 그 자체를 공급하는 것을 하드웨어 RAID라고 정의한다.
(2) 저렴한 가격의 제품도 존재하지만 안정적이고 성능이 좋은 제품은 여전히 가격대가 높다.
8-3. Software(S/W) RAID
(1) 고가의 하드웨어 RAID에 대한 대안으로, 하드 디스크만 있으면 운영체제에서 지원하는 방식으로 RAID를 구성하는 방법이다.
(2) 하드웨어 RAID와 비교하면 신뢰성이나 속도가 떨어질 수 있지만 저렴한 비용으로 더 안전하게 데이터를 저장할 수 있다는 점에서 고려해볼 수 있다.
8-4. RAID Level
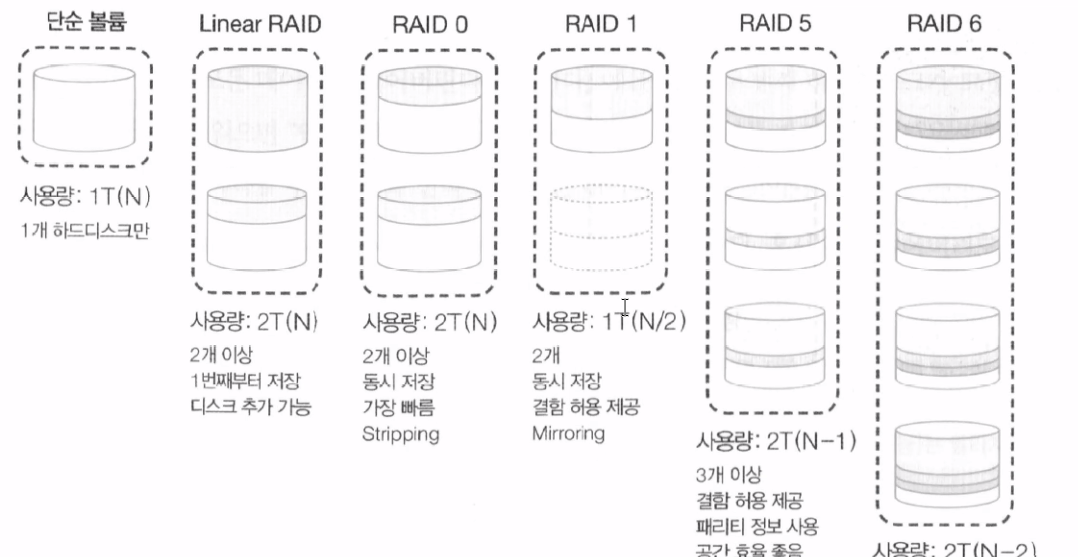
(1) RAID는 기본적으로 구성 방식에 따라 Linear RAID, RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5 총 7가지로 분류할 수 있다.
(2) 주로 사용되는 방식은 Linear RAID, Linear RAID 0, RAID 1, RAID 5, RAID 6, RAID 1+0이다.
8-5. Linear RAID & RAID 0

(1) 두 레벨 방식 모두 최소 2개의 하드 디스크가 필요하다. 2개 이상의 하드 디스크를 1개의 볼륨으로 사용한다는 점에서 비슷해 보이지만 저장되는 방식에 큰 차이점이 있다.
(2) Linear는 첫 번째 하드 디스크가 모두 채워진 이후에 두 번째 하드 디스크를 사용하기 시작하며 RAID 0 레벨은 각 데이터들이 첫 번째, 두 번째 ... n번째 하드 디스크에 동시에 저장되는 저장 방식을 가진다. RAID 0처럼 여러 개의 하드 디스크에 동시에 데이터가 저장되는 방식을 Stripping 방식이라고 한다.
8-6. RAID 1

(1) RAID 1의 핵심은 미러링(Mirroring)이다.
(2) 미러링 기술은 똑같은 데이터 거울을 세워둔다고 생각하면 쉽다. 예를 들어 12 바이트의 데이터 저장 시 2배 용량인 24 바이트가 소모되며 1 레벨 방식을 채택하면 총 하드 디스크 용량의 절반만 사용할 수 있다.
(3) 하드 디스크 2개를 보통 사용하는데, 2개 중 하나가 고장나더라도 데이터가 소실되지 않는다. 결함 허용(Fault-Tolerance)을 하고 있지만 최대 단점은 실제 설계한 데이터 공간의 2배가 필요하다는 것으로 공간 효율이 떨어진다는 점이 존재한다.
8-7. RAID 5

(1) RAID 5레벨의 경우 최소 3개 이상의 하드 디스크가 존재해야 구성할 수 있다.
(2) RAID 1처럼 어느 정도 안정성이 확보되면서 RAID 0처럼 공간 효율성도 요구하게 되었는데 이 부분을 충족하는 RAID 방식이 RAID 5다.
(3) 대부분 5개 이상의 하드 디스크로 구성하며 하드 디스크에 오류 발생 시 패리티 비트를 통해 복구를 수행한다.
9. LAB : RAID 0, RAID 1, RAID 5 Level
9-1. LAID 0
(1) 실습 이전 7개의 하드 디스크를 Setting 한다.
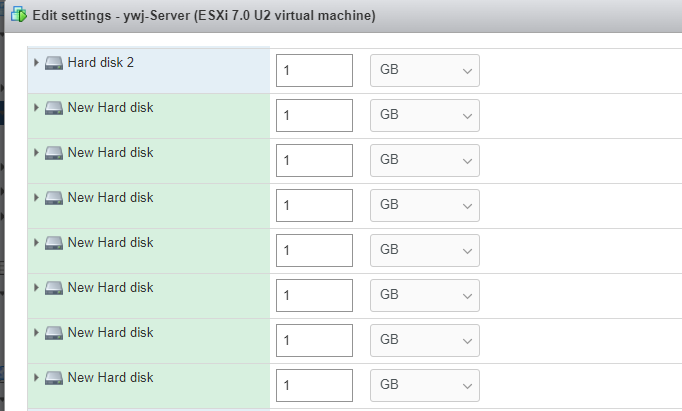
(2) ESXi 클라이언트에서 디스크를 구성하고 VMs를 재부팅한다.
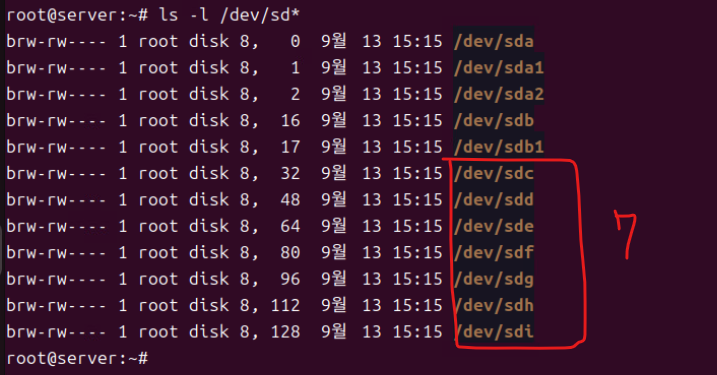
(3) /dev/sd*으로 파티션 확인
- 하드 디스크를 추가하면서 /dev 디렉터리를 기준으로 새로운 파티션이 생성된 것을 확인할 수 있다.
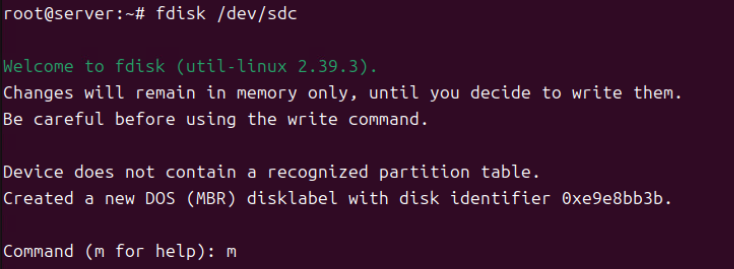
(4) m 커맨드를 줘서 파티션 테이블을 생성한다.
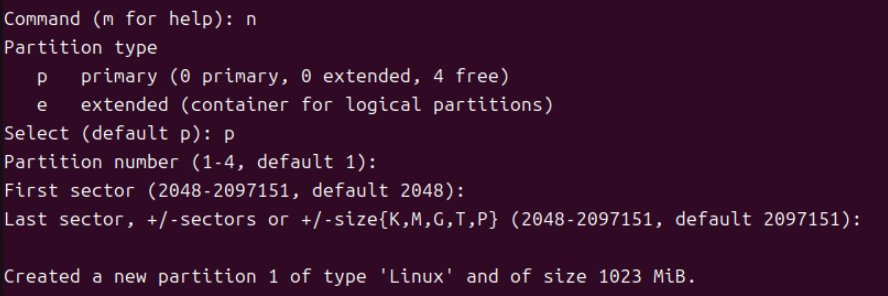
(5) n 커맨드로 파티션 타입을 p로 주고 First, Last sector 값을 모두 기본값으로 준다. (Sector 값의 경우 Enter 개행을 주면 자동으로 기본값이 지정된다.)

(6) t 커맨드로 해당 파티션에 대해 파일 시스템 유형을 변경할 수 있다.
(7) Hex 코드 fd는 파티션 테이블에서 "Linux raid autodetect"를 나타낸다. 이는 RAID 배열을 자동으로 감지할 수 있도록 설계된 파티션으로 주로 여러 디스크에 걸쳐 데이터를 분산 저장할 때 사용된다. 이 코드를 사용하는 파티션은 RAID 구성에 필수적이며, 시스템이 RAID를 정상적으로 인식할 수 있도록 한다.

(8) w 옵션으로 지금까지의 변경 사항을 모두 저장한다.
- 생성한 하드 디스크의 7개에 대해 위와 동일한 파티션, 파일 시스템 적용 작업을 수행한다.
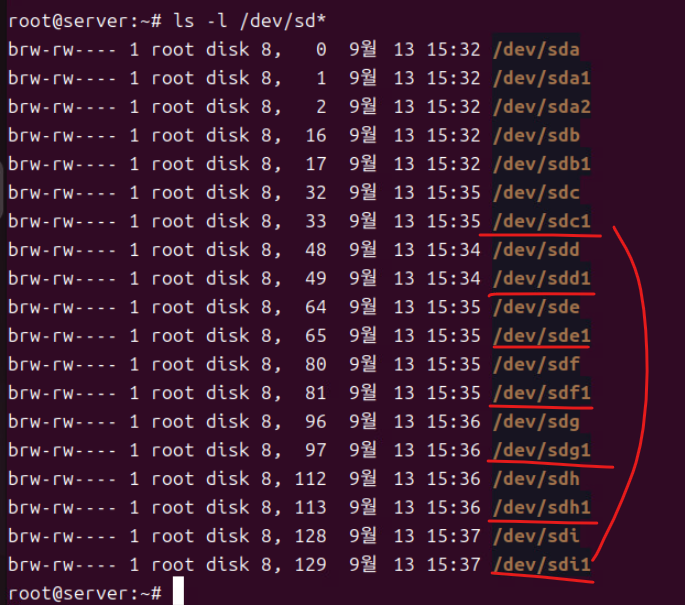
(9) 각각 하드 디스크에 대해 파티션 작업 수행하면 각 경로 뒤에 숫자 1이 붙는 새로운 파티션 테이블 경로가 생성된다.

(10) 이후 apt install mdadm을 통해 RAID 관리 도구를 설치한다.

(11) mkdir /raid0 명령으로 디렉터리를 우선 생성한 후 포맷 / 마운트를 진행하기 전 주의 사항이 있다.
- RAID 구성의 경우 마운트 진행 이전에 RAID 구성을 마친 후 ARRAY의 파일 시스템 경로가 재부팅 시 다시 한 번 변경되는 이슈가 있다. 따라서 마운트 진행 전 RAID 디스크를 구성한 상태에서 재부팅 후 RAID 디스크 포맷 / 마운트를 진행한다. (우분투 리눅스가 패치되면서 RAID 구성을 마친 후 ARRAY의 파일 시스템 경로가 재부팅 시 다시 한 번 변경되는 문제가 있는 듯 하다. 앞의 커맨드인 mdadm --detail --scan으로 확인 가능하다)
(12) mdadm --create /dev/md0 --level=0 --raid-devices=2 /dev/sdd1 /dev/sde1

(13) 재부팅 이전 /dev/md0으로 확인된다. 리부팅을 진행해 보자.

(14) 재부팅 후 --detail --scan을 다시 명령을 주면 경로가 /dev/md/server:0으로 변경되어 있는 것이 확인된다.

(15) 이후 mkfs.ext4 명령으로 포맷을 진행하며 ARRAY의 변경된 경로를 넣어준다.
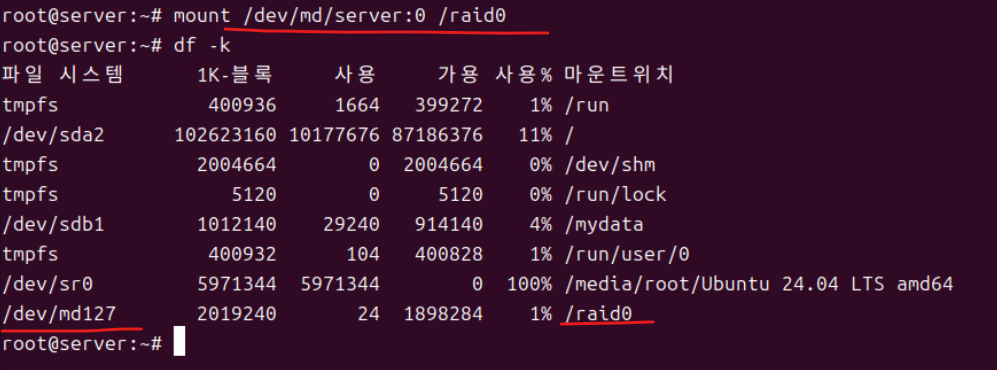
(16) 포맷 후 변경된 경로로 마운트하고 df -k로 디스크 현황을 확인한다.
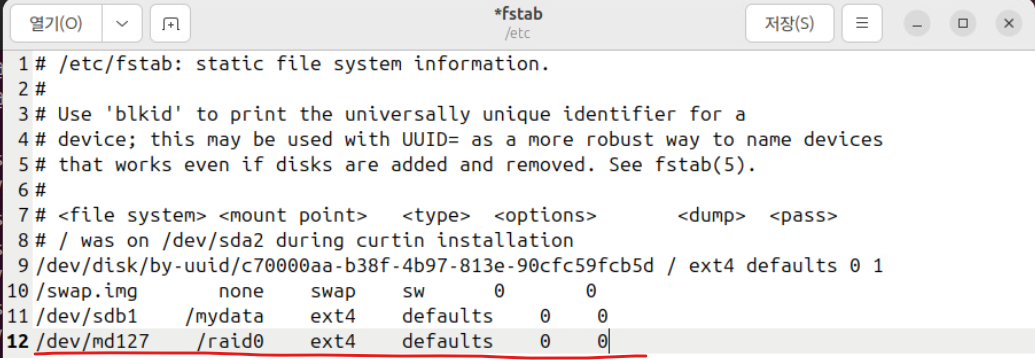
(17) 위와 같이 에디터를 편집해 주고 재부팅한다.
- 맨 첫 번째 영역에는 마운트된 파일 시스템 경로인 /dev/md127처럼 확인되는 경로를 넣어준다.

(18) 위와 같이 마운트한 디렉터리 경로들이 재부팅 이후에도 정상적으로 구동되는 것을 확인할 수 있다.
(19) RAID 0 작업이 완료된 서버에 대해 이전과 동일하게 스냅샷을 미리 생성해둔다.
9-2. RAID 1 구성
(1) 하드 디스크 등 파티션과 관련된 선처리 작업은 앞서 실습 환경에서 미리 구성되어 있다.
(2) /dev/sdf1, /dev/sdg1을 RAID 1 장치인 /dev/md1로 생성하고 생성 여부를 아래와 같이 확인한다.
> mdadm --create /dev/md1 --level=1 --raid-devices=2 /dev/sdf1 /dev/sdg1
> mdadm --detail --scan
(3) mkfs.ext4 /dev/md1 또는 mkfs -t ext4 /dev/md1 커맨드를 통해 /dev/md1 파티션 장치를 포맷한다.
(4) mkdir /raid1 커맨드를 통해 마운트 디렉터리를 생성하고 mount /dev/md1 /raid 커맨드를 통해 마운트를 진행한다.
(5) 이후 df -k로 마운트 내역을 확인한다.
(6) 재부팅 이후에도 마운팅 환경을 영구적으로 유지하기 위해 nano 또는 geditor를 통해 /etc/fstab 디렉터리를 열어서 아래와 같은 구문을 추가한다.
> /dev/md1 /raid1 ext4 defaults 0 0
9-3 RAID 5 구성
(1) RAID 1 구성 방식와 유사하지만 하드 디스크 개수를 3개로 맞춰서 실습을 진행한다.
(2) 아래 커맨드를 통해 /dev/sdh1, /dev/sdi1, /dev/sdj1을 RAID 5 장치인 /dev/md5로 생성한다.
> mdadm --create/dev/md5 --level=5 --raid-devices=3 /dev/sdh1 /dev/sdi1 /dev/sdj1
> mdadm --detail --scan
(3) 아래 커맨드를 통해 /dev/md5파티션 장치를 포맷한다.
> mkfs.ext4 /dev/md5
(4) 아래 명령으로 마운트 디렉터리를 생성하고 마운트를 진행한다.
> mkdir /raid5
> mount /dev/md5 /raid5
(5) 재부팅 이후에도 마운팅 환경을 영구적으로 유지하기 위해 nano 또는 geditor를 통해 /etc/fstab 디렉터리를 열어서 아래와 같은 구문을 추가한다.
> /dev/md5 /raid5 ext4 defaults 0 0
10. LVM(Logical Volume Manager) 개념 이해
10-1. LVM 개요
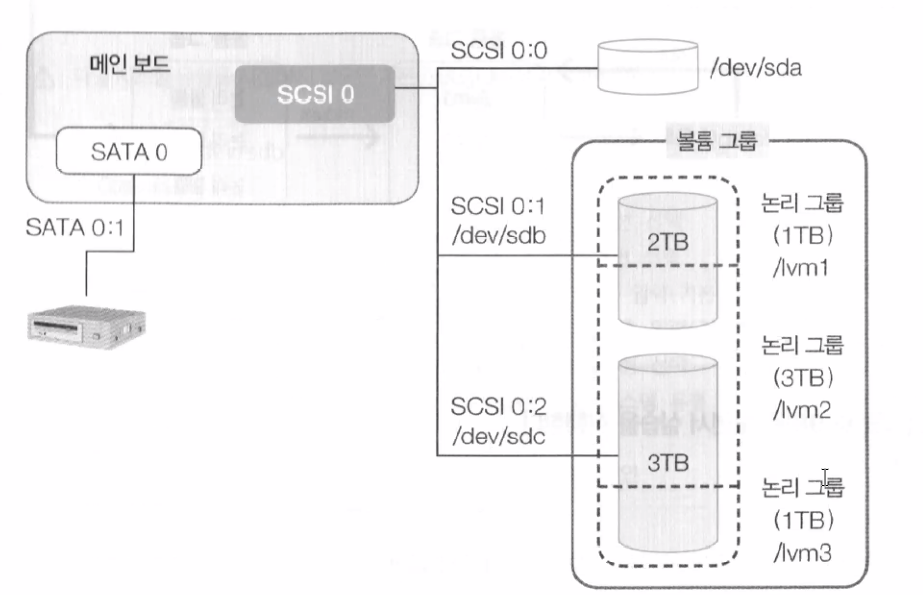
(1) LVM은 논리적인 하드 디스크 관리자라는 의미를 갖고 있는데 RAID와 비슷해 보이지만 더 많은 장점을 갖고 있다.
(2) LVM은 여러 개의 하드 디스크를 합쳐서 한 개의 파티션으로 구성한 후 다시 필요나 목적에 맞게 적절히 나누는 디스크 관리 기술을 말한다.
(3) Physical Volume
- /dev/sd1, /dev/sdb1 등의 물리적 파티션을 의미한다.
(4) Volume Group
- 물리 볼륨을 합쳐서 1개의 물리 그룹으로 생성한 것
(5) Logical Volume
- 볼륨 그룹을 1개 이상으로 나눈 것으로 논리적 그룹이라고도 한다.
10-2. LVM Implementation


(1) 물리적인 하드 디스크 2, 3GB를 각각 추가한다. (Thin Provisioned)

(2) 하드 디스크를 추가하고 재부팅한 뒤 ls -l /dev/sd*로 추가된 물리 디스크 확인한다.

(3) 이후 fdisk Manager에 접속해서 m > n > p >enter >enter > t > 8e > w (위 실습의 경우 /dev/sdb, /dev/sdc 모두 진행)
순으로 물리적 볼륨 레이블에 대해 파티션을 구성한다.
(4) 위와 같이 파티션을 생성한 후 ls -l /dev/sd*으로 생성된 파티션을 확인한다.

(5) apt -y install lvm2

(6) pvcreate /dev/sdb1, pvcreate /dev/sdc1 (물리 볼륨 생성)

(7) vgcreate myVG /dev/sdb1 /dev/sdc1 (볼륨 그룹 생성)
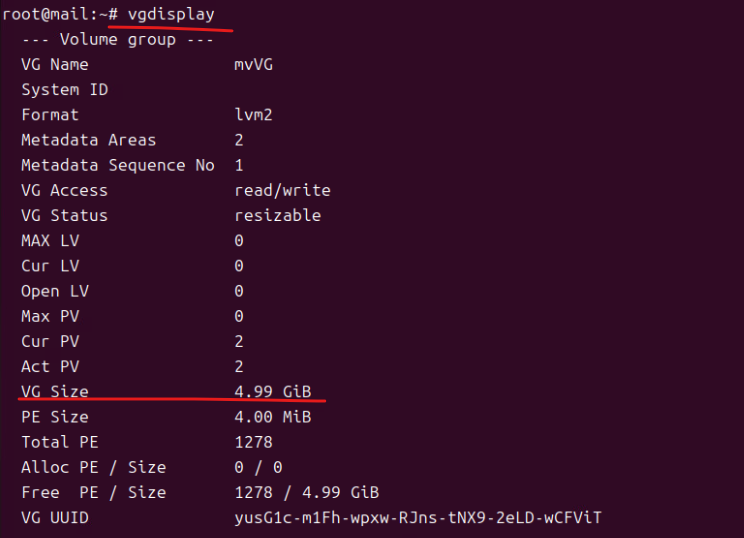
(8) vgdisplay를 통해 format = lv2 vg name = myVG, free PE Size = 4.99gb 인 부분을 확인한다.

(9) lvcreate --size 1G --name myLG1 myVG, lvcreate --size 3G --name myLG2 myVG
- myVG라는 볼륨 그룹 내에서 각 사이즈에 맞는 논리 볼륨을 생성한다.

(10) lvcreate --extents 100%FREE --name myLG3 myVG
- myVG 볼륨 그룹 내의 사용 가능한 모든 여유 공간을 사용해서 논리 볼륨을 생성한다.
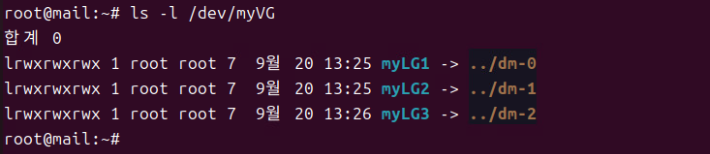
(11) ls -l /dev/myVG
- 해당 명령을 주면 링크 구성으로 만든 myLG?가 각각 확인된다.

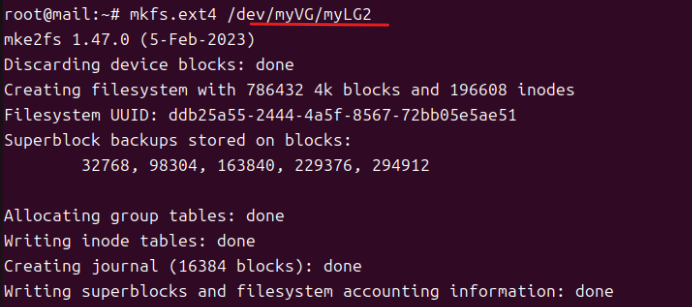

(12) mkfs.ext4 /dev/myVG/myLG1, mkfs.ext4 /dev/myVG/myLG2, mkfs.ext4 /dev/myVG/myLG3

(13) mkdir /lvm1 /lvm2 /lvm3

(14) mount /dev/myVG/myLG1 /lvm1, mount /dev/myVG/myLG2 /lvm2, mount /dev/myVG/myLG3 /lvm3

(15) df -k로 LVM 요소들 확인

(16) 현재까지 작업한 부분에 대해 Snapshot을 저장한다.
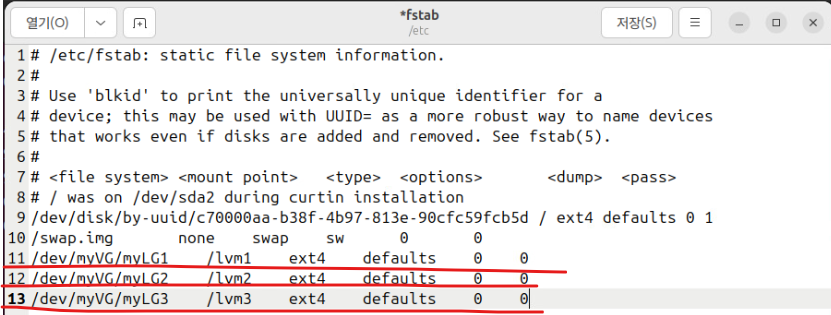
(17) geditor /etc/fstab에 각 내용 추가
/dev/myVG/myLG1 /lvm1 ext4 defaults 0 0
/dev/myVG/myLG2 /lvm2 ext4 defaults 0 0
/dev/myVG/myLG3 /lvm3 ext4 defaults 0 0

(18) 에디터를 저장한 후 시스템 재부팅 이후에 df -k로 확인 시 LVM history 확인된다.
(19) vgdisplay 명령 확인
(20) 현재 작업 진행 시 LVM 구성은 확인되지만 RAID 구성이 올바르게 확인되지 않는다 (LVM 설정 후 RAID 파일 시스템 경로가 또 변경됨에 따라 인식되지 않는 것으로 예상됨) 따라서 LVM 생성 후 마운트 이전에 재부팅을 해서 RAID 파일 시스템 경로를 다시 /etc/fstab에서 바꿔준 뒤 LVM의 포맷/마운트 진행
(21) 우선 RAID / LVM을 동시에 구성하는 경우는 많이 없고 동시에 구성한다 하더라도 재부팅 때문에 파일 시스템 경로가 변경되어 구성 정보가 사라지는 경우는 운영체제가 버전업되면서 발생하는 이슈일 수도 있기 때문에 이러한 부분은 우선 무시하고 RAID & LVM 각 디스크 관리 방식의 의미, 구성 방법 등 & 관련 명령어만 확인해 둔다.
12. Reference
(1) https://www.hanbit.co.kr/store/books/look.php?p_code=B3658372395
이것이 우분투 리눅스다(개정판)
1대의 컴퓨터에 4개의 가상머신을 생성! \\\'실무형 실습 환경\\\'에서 초보자도 막힘없이 실습할 수 있다.
www.hanbit.co.kr
※ 해당 포스팅을 기준으로 내용 추가가 필요하다고 생각되면 기존 내용에 다른 내용이 추가될 수 있습니다.
개인적으로 공부하며 정리한 내용이기에 오타나 틀린 부분이 있을 수 있으며, 이에 대해 댓글로 알려주시면 감사하겠습니다!