과목명 : 컴퓨터 구조(Computer Organization & Architecture)
수업일자 : 2022년 09월 15일 (목)
1. 컴퓨터 시스템의 성능(Performance)
1-1 성능 균형(Performance balance)
- 프로세서의 능력이 매우 빠른 속도로 발전하고 있으나 다른 주요 부품들은 그에 따라가지 못하고 있으며 이러한 문제를 해결하기 위해서는 다양한 구성요소들의 불일치(Dismatch)를 보상해 주어야 하며 컴퓨터 조직과 구조를 적절히 조절/튜닝해 주어야 합니다.
- 메모리와 프로세서(CPU) 간의 인터페이스에서 이러한 불일치가 심각한 상태입니다.
- 프로세서 속도와 메모리의 용량히 급격히 증가한 반면, 메모리의 데이터 전송 속도는 프로세서의 데이터 전송 속도보다 많이 뒤떨어진 편입니다.

1-2 메모리와 프로세서 간의 성능 균형을 맞추기 위한 해결 방안
(1) DRAM의 버스 데이터 통로를 더 넓게 설계함으로써, 한 번에 가져올 수 있는 비트 수를 늘린다.
- 더 넓은 데이터 통로를 사용하는 것입니다.
(2) 상호 연결 대역폭 증가
- 프로세서와 기억장치 사이에 더 빠른 속도의 버스들을 사용하거나, 계층적 버스를 사용하여 데이터 흐름을 조직화함으로써 상호연결 대역폭을 증가시키는 것입니다.
(3) 기억 장치의 엑세스 빈도 수를 줄인다.
- 프로세서와 메모리 사이에 복잡하고 효율적인 캐시 조직을 배치함으로써 기억장치 엑세스의 빈도 수를 줄입니다. 프로세서 근처에 칩-외부 캐시(Off-chip cache)를 두는 것뿐만이 아닌 프로세서의 칩 내에도 한 개 또는 그 이상의 캐시들을 넣는 것도 포함됩니다.
1-3 I/O 장치 (입출력 장치)와 프로세서 간 발생하는 성능 차이
- 컴퓨터들이 더 빨라지고 능력이 향상됨에 따라 높은 I/O 요구율(Request rate)를 필요로 하는 응용 프로그램들이 개발되었습니다.
현 세대의 프로세서들은 이러한 장치들로부터 발생되는 데이터를 처리할 순 있지만 프로세서와 주변 장치 사이에 데이터를 이동시키는 문제는 여전히 남아 있습니다.
해결책)
- 캐싱(Caching) / 버퍼링(Buffering) 방법
- 더 높은 속도의 상호 연결 버스를 사용
- 추가적인 버스 구조 개선
- 다중 프로세서 구조 배치
1-4 전형적인 I/O 장치(입출력 장치)들의 데이터율(Data rate)
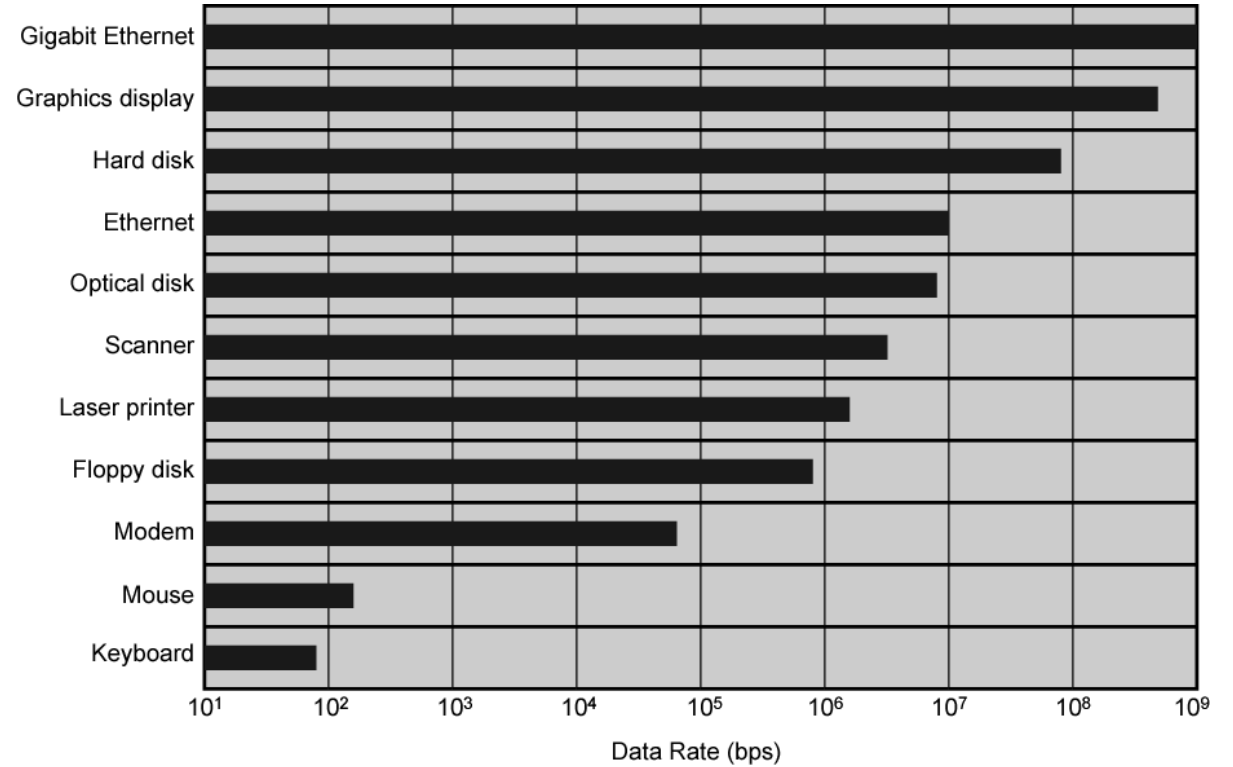
2. 프로세서 속도를 높이기 위한 방법
설계과정에서 프로세서의 성능을 주 기억장치 및 다른 컴퓨터 구성요소들의 성능과 균형을 맞추는데 집중하고 있는 동안에 프로세서의 속도를 높일 필요성도 여전히 존재합니다.
(1) 프로세서의 하드웨어 속도를 증가시킨다.
- 근본적으로 칩 상의 논리 게이트들의 크기를 더 줄이고 더 많은 게이트들을 집적시켜 클럭 속도를 높이는 방법입니다.
- 신호들의 전파 시간이 감소합니다.
(2) 프로세서와 주 기억장치 사이에 위치하는 캐시의 크기와 속도를 증가시킨다.
- 프로세서 칩 자체의 한 영역을 캐시에 할애한다면 캐시 엑세스 시간이 감소하게 됩니다.
(3) 프로세서 조직과 구조를 변경한다.
- 전형적으로 이를 위해서는 한 두 가지 형태의 병렬성을 이용하는 것이 포함된다
- Ex) 명령어 파이프라인(Instruction pipeline)
2-1 클럭속도와 회로 밀도의 문제
(1) 전력(Power)
- 내부 회로의 밀도와 클럭 속도가 높아지면 전력 밀도 증가함에 따라 많은 열이 발생하는데 있어 이 열을 처리해야 하는 부분도 심각한 설계 이슈가 되고 있습니다.
(2) RC 지연(RC Delay)
- 칩 상에서 트랜지스터들 간에 흐르는 전자들의 속도는 그들을 연결해 주는 금속선들의 저항과 커패시턴스에 의해 제한됩니다.
- RC 곱의 값이 증가함에 따라 지연도 길어집니다.
- 이에 따라 연결선들은 더 가늘어져서 저항이 증가하게 됩니다.
- 선들이 더 가까이 위치하면 커패시턴스도 함께 증가합니다
(3) 기억장치 지연(Memory latency)과 처리율(Throughput)
- 기억장치 엑세스 속도(지연)와 전송속도(처리율)은 프로세서 속도보다 떨어집니다.
해결책)
- 따라서 성능을 향상시키기 위해 조직 및 구조적 방법을 사용하는 것이 더 강조되고 있습니다.
2-2 인텔 마이크로프로세서 성능

3. 성능 향상을 위한 조직 및 구조적 방법
(1) 캐시 용량을 증가시킨다.
- 프로세서와 주 기억장치 사이에는 두 레벨 혹은 세 레벨의 캐시들이 설치됩니다.
- 칩 밀도가 높아질수록, 더 많은 캐시 기억장치가 내부로 들어가게 됨으로써 캐시 엑세스 속도가 더 향상됩니다.
(2) 파이프라이닝(Pipelining)과 슈퍼스칼라(Superscalar)
- 파이프라이닝은 생산 공장의 조립 라인과 유사하게 동작하며 파이프라인을 따라 여러 단계들에서 서로 다른 명령어들이 동시에 실행되게 합니다.
- 슈퍼스칼라 방식은 하나의 프로세서 내부에 여러 개의 파이프라인을 두어 서로 의존관계가 없는 명령어들이 병렬로 실행되게 합니다
(3) 위의 두 가지 방식들의 한계점 도달
- 최신 프로세서들의 내부 조직의 복잡성 증가
명령어의 흐름(Instruction stream)으로부터 병렬성을 이끌어 내고 있었으나 이 방향으로는 큰 향상을 기대하기 힘들게 되었습니다
- 프로세서 칩에 세 레벨의 캐시를 두고 캐시로부터 이득을 얻는 부분도 한계에 도달하게 되었습니다.
- 성능 향상을 위해 클럭 속도를 높이는 부분의 어려움
클럭 속도가 증가할수록, 소모되는 전력량은 높아지며 여러 가지 물리적 한계에 도달하게 되며 어려움이 생기게 되었습니다.
(4) 새로운 시도, 멀티 코어(Multicore)
- 위와 같은 어려움 속에서도 설계자들은 큰 용량의 캐시를 공유하는 여러 프로세서들을 같은 칩에 넣는 방법을 생각하게 되었으며 동일 칩 상에 다수의 프로세서를 두는 방식은 다중 코어(Multiple cores), 멀티 코어(Multicore)라고 부릅니다.
해당 방식은 클럭 속도를 높이지 않고도 성능을 향상시킬 수 있는 가능성을 열어준다.
- 프로세서 수를 두 배로 늘리면 성능도 거의 두 배로 늘어납니다.
- 프로세서 내부에서의 성능 향상은 복잡도 증가의 제곱근에 비례하는 것으로 확인되었습니다.
- 이와 같이 해당 전략은 하나의 복잡한 프로세서를 이용하기 보다는 칩 상에서 더 간단한 두 개의 프로세서를 이용하자는 것입니다.
4. 성능 평가
(1) 새로운 시스템을 선택하기 위한 요구 사항
- 가격
- 크기
- 보안성
- 신뢰성 및 전력 소모량
- 성능
(2) 프로세서의 응용 성능
- 프로세서의 응용 성능은 프로세서 자체에만 달려있는 것이 아닌, 응용 프로그램을 효율적으로 구현하기 위한 명령어 세트, 구현 언어의 선택, 컴파일러의 효율, 프로그래밍 구현 기술(자료구조, 알고리즘)에도 영향을 받게 됩니다.
4-1 클록 속도
- 프로세서에 의해 수행되는 모든 연산(명령어 인출, 해독, 산술연산 수행)들은 시스템 클록에 의해 통제됩니다.
이에 따라 모든 연산들은 시스템 클록의 펄스와 함께 시작합니다.
- 프로세서의 속도는 클록에 의해 발생되는 펄스 주파수(초당 사이클 수, 또는 Hz(헤르츠)로 측정)에 의해 결정됩니다.
4-2 명령어 실행율(Millions of instructions per second, MIPS)
- 프로세서는 클록에 의해 구동됩니다.


4-3 MFLOPS(Millions of floating-point operations per second)
- 해당 성능 척도는 부동소수점 명령어들만을 대상으로 합니다.
- 해당 지표는 수학, 과학 및 게임 응용 분야에서 널리 사용됩니다.

4-4 성능에 영향을 미치는 요소
(1) 명령어 수
- 하나의 프로그램을 수행하기 위해서 필요한 명령어의 개수입니다.
- 명령어 세트 구조
- 컴파일러 기술 : 컴파일러가 고급 프로그래밍 언어로부터 얼마나 효과적으로 머신 코드로 번역하는지에 대한 부분
(2) CPI(Cycles Per Instruction)
- 하나의 명령어를 수행하기 위해 소요되는 클럭 사이클의 수를 의미합니다.
- 명령어 세트 구조
- 컴파일러 기술
- 프로세서 구현
- 캐시 및 기억장치 계층
(3) 사이클 시간(클록율)
- 하드웨어 구성 및 구현 기술에 의존한 지표입니다.
4-5 명령어 세트의 차이
(1) RISC(Reduced Instruction Set Computer)
- RISC는 말 그대로 축소 명령어 컴퓨터 세트를 의미합니다.
- 명령어 세트가 축소되었으며 핵심적인 명령어를 기반으로 최소한의 명령어 세트를 구성함으로써 파이프라이닝이라는 획기적인 기술을 도입하게 되면서 빠른 동작속도와 하드웨어 단순화, 효율을 극대화할 수 있었습니다.
(2) RISC의 특징
- 적은 명령어 세트
- 간단한 명령어로 빠른 실행 속도 보장
- 회로 구성의 단순함
- 프로그램을 구성할 때 상대적으로 많은 명령어를 필요로 한다.
- 명령어의 개수가 적어서 컴파일러를 단순히 구현할 수 있다.
(3) CISC(Complex Instruction Set Computer)
- 연산을 처리하는 복잡한 명령어들을 수 백 개 이상 탑재하고 있는 프로세서를 의미합니다.
- CISC는 명령어의 개수가 증가함에 따라 프로세서 내부가 매우 복잡해지는 특징이 있습니다.
(4) CISC의 특징
- 명령어의 개수가 많음
- 명령어의 길이가 다양하며 실행 사이클도 이에 따라 달라진다.
- 회로 구성이 복잡하다.
- 프로그램을 구성할 때 적은 명령어로도 구현이 가능하다.
- 다양한 명령어의 사용으로 컴파일러가 복잡하게 구현된다.
- 학부에서 수강했던 전공 수업 내용을 정리하는 포스팅입니다.
- 내용 중에서 오타 또는 잘못된 내용이 있을 시 지적해 주시기 바랍니다.
'전공 수업 > 컴퓨터 구조(Computer Architecture)' 카테고리의 다른 글
| [6주 차] - 메모리(데이터) 참조 지역성, 캐시(Cache) 메모리 (1) (0) | 2022.10.18 |
|---|---|
| [5주 차] - 컴퓨터의 기능과 상호 연결 (2), 기억 장치 시스템의 특성 (0) | 2022.10.02 |
| [4주 차] - 컴퓨터 시스템의 성능 (2), 컴퓨터의 기능과 상호 연결 (1) (4) | 2022.09.25 |
| [2주 차] - 컴퓨터 시스템의 조직과 역사 (0) | 2022.09.12 |
| [1주 차] - 수업 개요 (0) | 2022.09.01 |



댓글