과목명 : 컴퓨터 구조(Computer Organization & Architecture)
수업일자 : 2022년 11월 24일 (목)
< 기계(프로세서) 명령어 세트(Machine(processor) instruction set) chapter list>
(A) 기계 명령어의 특성
(B) 오퍼랜드(Operand)의 종류
(C) 연산의 종류
- 데이터 전송(Data transfer)
- 산술(Arithmetic operation)
- 논리(Logical operation)
- 변환(Conversion)
- 입력과 출력(Input & Output)
- 시스템의 제어(Control of system)
- 제어의 이동(Transfer of control)
1. 기계 명령어의 특성
1-1. 개요

(1) 시스템 설계자
- 프로세서에 대한 기능적 요구 사항들을 제시합니다.
- 프로세서를 구현하는 것은 기계 명령어 세트를 구현하는 것으로 생각할 수 있습니다.
(2) 시스템 개발자
- 어셈블리어로 프로그래밍을 하는 개발자 입장에서는 레지스터 및 메모리의 조직, 컴퓨터가 직접 지원하는 데이터 형식 및 ALU를 알 수 있게 됩니다.
1-2. 기계 명령어, 명령어 세트의 뜻
- 프로세서의 연산은 실행하는 명령어들에 의해 결정되며 그들은 기계 명령어(Machine instruction)라고 불립니다. 프로세서가 실행할 수 있는 여러 가지 명령어들의 집합을 명령어 세트(Instruction set)라고 합니다.
- 만약 기계 명령어가 2진수(Binary number)의 형태로 표현된다면 이들은 프로세서가 바로 이해하고 실행할 수 있는 기계어(Machine code)라고 부릅니다.
- 이러한 기계 명령어들은 어셈블리어(Assembly language)로 표현됩니다.
1-3. 기계 명령어의 요소들
(1) 연산 코드(Operation code)
- 수행될 연산의 형태를 지정합니다. (Ex : ADD, I/O)
- 연산은 연산 코드 또는 Opcode라고 불리는 2진 코드에 의해 저장됩니다.
(2) 원천 오퍼랜드 참조(Source operand reference)
- 각 연산들은 해당 연산을 위한 입력이 되는 한 개 또는 그 이상의 오퍼랜드(Operand)들을 포함합니다.
(3) 결과 오퍼랜드 참조(Result operand reference)
- 연산에 대한 결과를 생성합니다.
(4) 다음 명령어 참조(Next instruction reference)
- 프로세서에게 현재 명령어 실행이 완료된 후, 다음 명령어를 인출할 위치를 알려줍니다.
(프로그램 카운터(Program counter, PC) 레지스터)
1-4. 원천 / 결과 오퍼랜드의 위치 (주소 지정 방식)
(1) 주기억장치 혹은 가상 기억장치에 위치
- 다음 명령어의 주소를 지정할 때와 마찬가지로 주기억장치 또는 가상 기억장치의 주소가 제공되어야 합니다.
(2) 프로세서 레지스터에 위치
- 1개의 레지스터 : 참조는 묵시적으로 이루어집니다.
- 1개 이상의 레지스터 : 각 레지스터의 고유 명칭 또는 번호 지정, 명령어는 레지스터의 번호를 포함합니다.
(3) 즉시(Immediate) 위치
- 실행될 명령어 내의 한 필드에 저장합니다.
(4) I/O 장치에 위치
- I/O 모듈과 장치를 지정해야 합니다.
1-5. 명령어 사이클의 상태도(State diagram of instruction cycle)
(1) 명령어 처리 순서의 관점
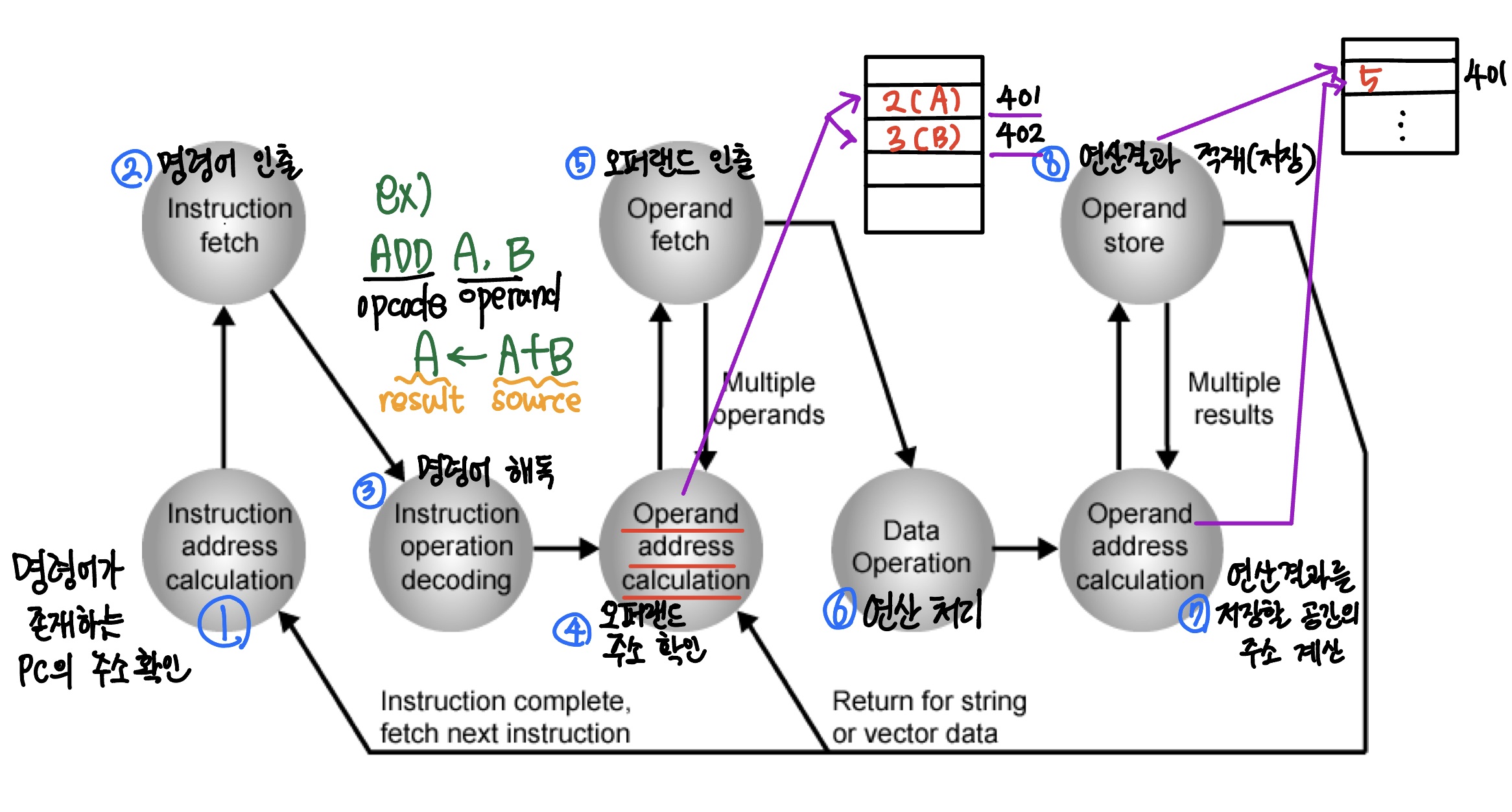
(2) 각 과정들의 또 다른 관점
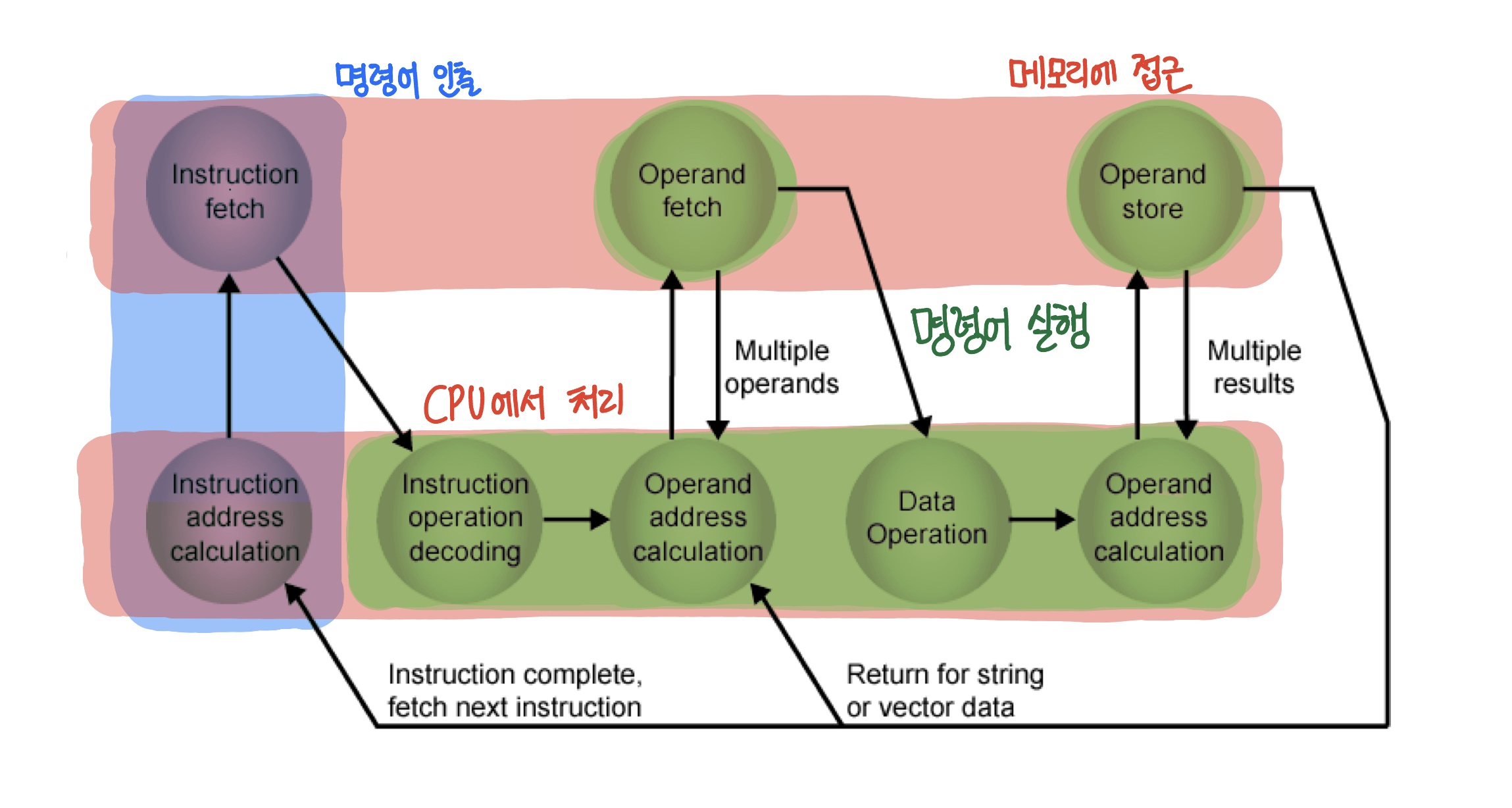
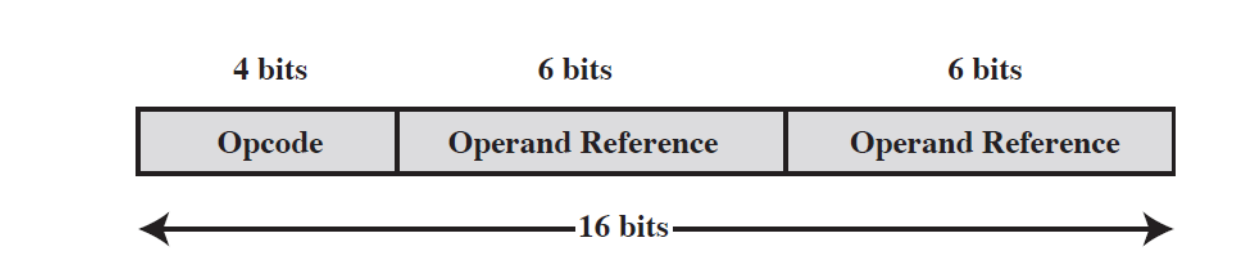
1-6 . 명령어 표현
(1) 명령어는 일련의 비트들에 의해서 표현됩니다.
- 명령어 세트들에서 한 가지 이상의 형식이 사용되며 명령어는 필드 형태로 구성됩니다.
(2) 2진 표현 대신 기호적 표현(Symbolic representation)을 사용합니다.
(3) 연산 코드(Opcode)
- 연산을 지정하는 니모닉(Mnemonics)으로 불리는 약어로 표현됩니다.
- 예시) ADD, SUB, MUL, DIV, LOAD, STOR
(4) 오퍼랜드도 기호적으로 표현합니다.
- 예시) ADD R, Y(R ← R + Y)
- R : 특정 레지스터, Y : 기억장치 내부의 어떤 위치의 주소
1-7. 고급 언어(High-level language), 기계 명령어(Machine instruction)
- Example) BASIC 또는 FORTRAN으로 작성된 경우 : X = X + Y (주소 공간 X = 513, Y= 514)
(1) 기계 명령어 수행 과정
- 레지스터에 주소 공간 513번지의 내용을 적재한다.
- 주소 공간 514번지의 내용을 레지스터의 내용과 더한다.
- 레지스터의 내용을 주소 공간 513에 저장한다.
(2) 기계 명령어 세트는 고급 언어의 어떤 명령 표현도 수행할 수 있을만큼 충분해야 합니다.
1-8. 명령어의 종류
(1) 데이터 처리
- 산술 명령어 : 수치 데이터를 처리하기 위한 계산 기능을 제공합니다.
- 논리 명령어 : 단어의 비트에 대해 수가 아닌 비트로써 연산 기능을 제공합니다.
(2) 데이터 저장
- 기억 장치와 레지스터 간의 데이터 이동 기능
(3) 데이터 이동
- I/O 명령어들 : 프로그램이나 데이터를 기억 장치로 옮기고 계산 결과를 사용자에게 반환합니다.
(4) 프로그램 제어
- 검사 명령어 : 데이터 값의 검사나, 계산 상태를 검사합니다.
- 분기 명령어 : 어떤 결정에 따라 다른 명령어 세트로 분기하는데 사용됩니다.
1-9. 주소의 개수
(1) 프로세서의 구조를 설명할 수 있는 전형적인 방법 중 하나입니다.
(2) 한 명령어에 필요한 주소
- 오퍼랜드 참조를 위한 주소 (최대 2개)
- 연산 결과 저장을 위한 주소
- 다음 명령어를 인출하기 위한 주소
1-10. 3주소 명령어

- 2, 3번째 주소 위치는 오퍼랜드의 위치를 지정합니다.
- 1번째 주소 위치는 결과를 저장할 위치를 지정합니다.
- 상대적으로 긴 명령어로 이루어져 있으며 잘 사용되지 않습니다.
1-11. 2주소 명령어
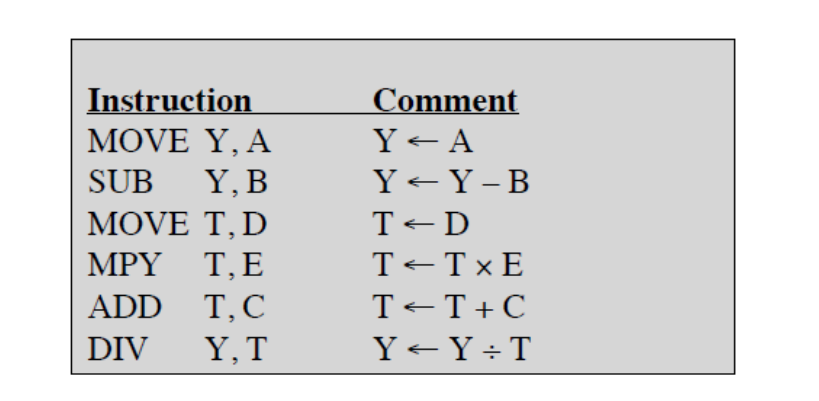
- 주소 하나가 오퍼랜드 주소와 결과값의 주소를 모두 지정합니다.
- 명령어의 길이는 줄어들었으나 명령어의 개수가 증가하게 됩니다.
1-12. 1주소 명령어
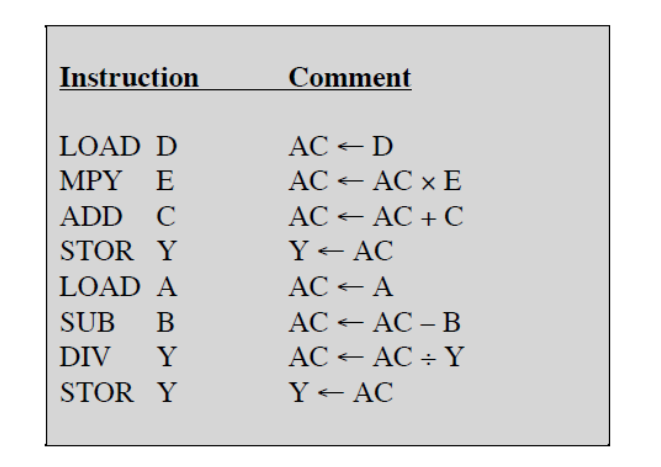
- 초기 컴퓨터에 흔히 사용되던 주소 체계입니다.
- 두 번째 주소는 묵시적인 형태로 구성됩니다.
(보통 누산기(Accmulator, AC)가 주소로 사용되었습니다.)
1-13. 0(Zero) 주소 명령어

- 모든 주소가 묵시적인 형태로 구성되어 있는 주소 명령어 체계입니다.
- 스택(Stack)을 사용하며 후입 선출(LIFO, Last In First Out)의 구조를 가지고 있습니다.
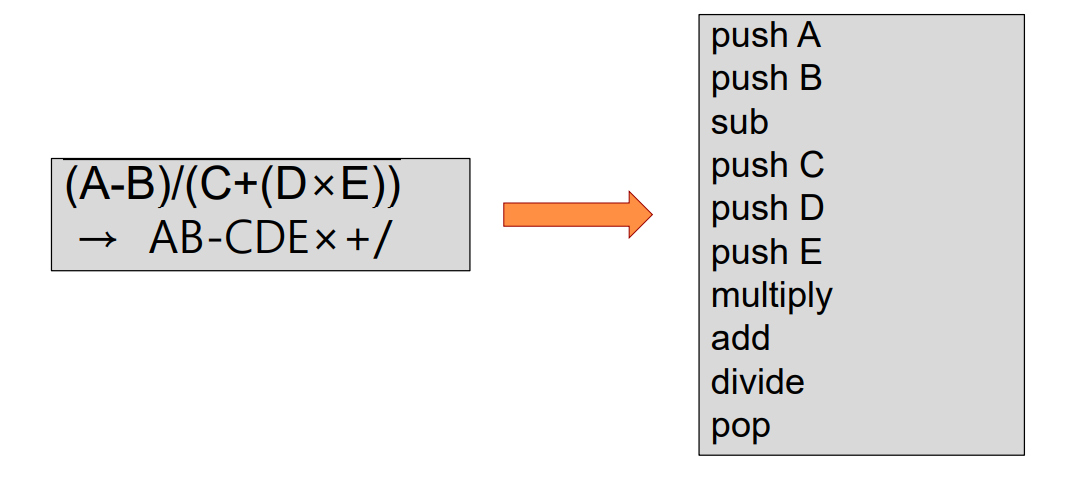
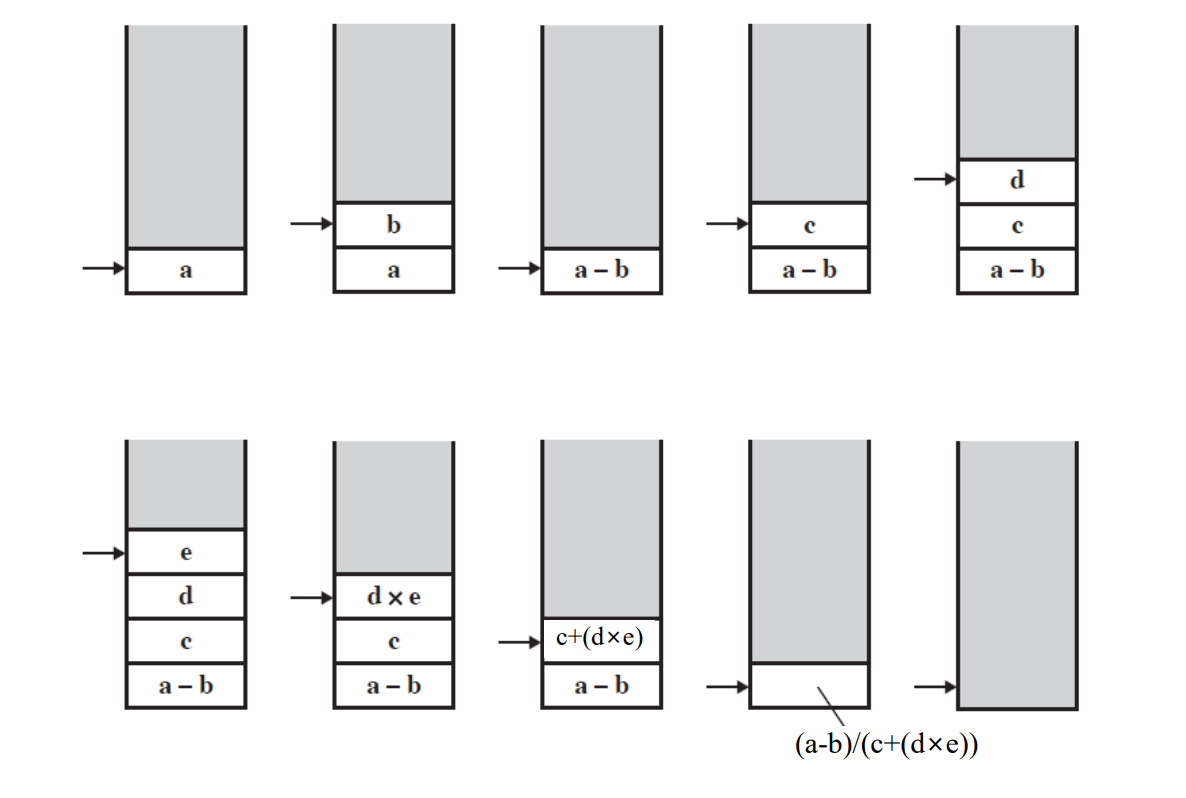
(1) 예시) (A - B) / (C + (D x E))의 처리 결과는?
- 0 주소 명령어의 연산 처리 방법 : 좌측에서 우측으로 처리합니다.
- 요소가 변수 또는 상수인 경우 : 스택에 PUSH
- 요소가 연산자인 경우 : 스택의 최상위에 있는 두 요소를 POP한 후 해당 연산을 수행하고 다시 스택에 PUSH합니다.
1-14. 주소의 개수 선택 문제 발생
(1) 주소 수 증가
- 더 복잡한 명령어의 구조
- 처리를 위한 레지스터 개수 증가 : 여러 개의 레지스터를 사용하면서 실행 속도가 향상됩니다.
- 프로그램 당, 명령어의 수가 감소합니다.
(2) 주소 수 감소
- 상대적으로 덜 복잡한 명령어 구조
- 명령어 길이 감소
- 프로그램 당 명령어의 수가 증가합니다.
- 명령어의 빠른 인출과 실행이 가능합니다.
(3) 최근 컴퓨터들은 2, 3주소 명령어 체계를 혼합해서 사용하고 있습니다.
1-15. 명령어 세트의 설계
(1) 연산 종류(Operation type)
- 얼마나 많은 연산이 제공되는지에 대한 부분
- 어떤 연산이 제공되는지에 대한 부분
- 얼마나 복잡한 연산이 제공되는지에 대한 부분
(2) 데이터 유형(Data type)
(3) 명령어 형식(Instruction formats)
- 연산 코드 필드의 길이
- 주소의 개수
(4) 레지스터(Register)
- 사용 가능한 프로세서의 레지스터의 개수
- 어떤 레지스터에 대한 연산 수행이 가능한지에 대한 부분
(5) 주소 지정(Addressing)
- 오퍼랜드의 주소가 지정되는 방식에 대한 부분
1-16. CISC(Complex Instruction Set Computer) 방식
- 마이크로 프로그래밍을 통해 고급 레벨 언어들에 대해 이에 맞는 기계어를 대응시켰습니다.
- 명령어의 집합이 커지고, 가변 길이의 다양한 명령어 형식을 가진 명령어 체계입니다.
- 구조가 복잡하고 가격이 비싸며 전력 소모가 큰 방식입니다.
- 인텔 계열 프로세서에 사용됩니다.
1-17. RISC(Reduced Instruction Set Computer) 방식
- 고정된 길이 형식의 명령어 형식을 보유한 명령어 체계입니다.
- 제어 장치 구현이 비교적 간단하며, 저전력, 임베디드 프로세서에 적합합니다.
- 자주 사용되는 명령어들을 간략화하여 프로세서의 성능을 극대화한 방식입니다.
- IBM System/6000 기종, 애플의 매킨토시 컴퓨터에 RISC 방식이 사용되었습니다.
2. 오퍼랜드의 종류
2-1. 주소
2-2. 수(Numbers)
- 정수 / 부동 소수점
2-3. 문자
- ASCII 방식 등
2-4. 논리적 데이터
- N 비트 단위를 각 항목이 0 또는 1을 가지는 n개의 1비트 데이터 항목
- Bits or flags
3. 연산의 종류
3-1. 연산의 여러 가지 종류
(1) 데이터 전송
(2) 산술 연산
(3) 논리 연산
(4) 제어의 이동
(5) 입력과 출력
(6) 변환
(7) 시스템 제어
3-2. 데이터 전송(Data transfer)
(1) 데이터 전송 명령어가 명시해야 할 사항들
- 근원지 및 목적지, 오퍼랜드의 위치 : 기억 장치, 레지스터, 스택의 최상위 위치 등
- 전송될 데이터의 길이
- 각 오퍼랜드의 주소 지정 방식
(2) 프로세서의 동작
- 오퍼랜드의 근원지/목적지가 레지스터라면 프로세서 내부에서 레지스터 간에 데이터 교환을 수행합니다.
- 오퍼랜드의 주소가 기억 장치 내부에 존재한다면, 아래 과정의 일부 / 전체를 수행하게 됩니다.
(a) 주소 지정 방식에 근거하여 기억 장치의 주소를 계산합니다.
(b) 만약 주소가 가상 기억 장치를 참조한다면 가상 주소를 실제 기억 장치 주소로 변환합니다.
(c) 주소 지정된 항목이 캐시에 있는지 확인합니다.
(d) 캐시에 없다면 기억 장치 모듈로 명령을 보냅니다.
3-3. 산술 연산(Arithmetic operation)
(1) 덧셈, 뺄셈, 곱셈, 나눗셈
(2) 부호를 가진 정수, 부동 소수점(Floating-point)
(3) 이외에 단일 오퍼랜드 명령어들
- Absolute
- Increment (변수 a가 존재한다면, a++)
- Decrement (변수 a가 존재한다면, a--)
- Negate (변수 a가 존재한다면 변수 a의 부호를 반대로 변경)
(4) 오퍼랜드를 ALU의 입력으로 Load하는 것과, ALU의 출력을 Store하는 행위까지 모두 포함됩니다.
3-4. 논리 연산(Logical operation)
(1) 비트 연산(Bitwise operations)
(2) AND, OR, NOT
(3) 기본적인 논리 연산들
| P | Q | NOT P | P AND Q | P OR Q | P XOR Q | P = Q |
| 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 0 | 1 | 1 | 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 | 1 | 0 |
| 1 | 1 | 0 | 1 | 1 | 0 | 1 |
3-5. Shift and Rotate operations
(1) 논리적 좌 / 우측 Shift
(2) 산술적 좌 / 우측 Shift
(3) 좌 / 우측 Rotate(Cyclic shift)
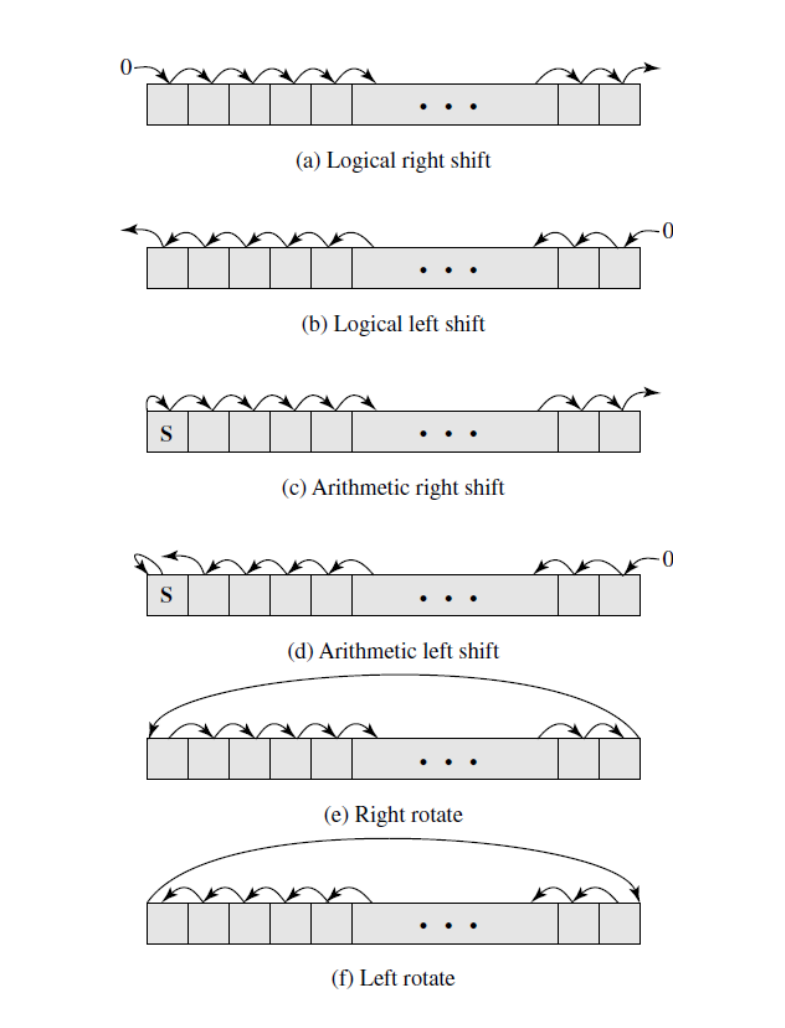
| 입력 | 연산 형태 | 결과(출력) |
| 10100110 | Logical right shift (3 bits) | 00010100 |
| 10100110 | Logical left shift (3 bits) | 00110000 |
| 10100110 | Arithmetic right shift (3 bits) | 11110100 |
| 10100110 | Arithmetic left shift (3 bits) | 10110000 |
| 10100110 | Right rotate (3 bits) | 11010100 |
| 10100110 | Left rotate (3 bits) | 00110101 |
(4) 논리적 좌측/우측 Shift 연산
- 단어의 비트들을 좌측 또는 우측으로 Shift 연산합니다.
- 한쪽 끝으로 Shift되어 나가는 비트는 잃어버립니다.
- 반대편 끝에는 0이 Shift되어 들어오게 됩니다.
- 단어 내의 특정 필드들을 격리시킬 때 주로 사용하게 됩니다.
3-5. 논리적 Shift 연산의 사용 예시
(1) Example) 한 번에 한 문자씩 I/O 장치로 문자를 전송하는 경우
- 각 기억장치 단어의 길이가 16비트이고 두 개의 문자를 저장한다면, 해당 문자들은 전송되기 전에 분리되어야 합니다.
- 한 단어 내에 저장된 후, 두 개의 문자들을 출력장치로 전송하기 위해 아래와 같이 진행됩니다.
(2) 좌측 문자 출력
- 그 단어를 레지스터에 적재합니다.
- 우측으로 8회 시프트합니다. 이 동작은 남아있던 문자를 레지스터의 우측 방향으로 시프트시킵니다.
- I/O를 수행하고 I/O 모듈은 하위 8비트들을 읽게 됩니다.
(3) 우측 문자 전송
- 단어를 다시 레지스터에 적재시킵니다.
- 0000000011111111과 AND 연산을 진행합니다. 해당 연산은 좌측 문자를 제거하게 됩니다.
- I/O를 수행합니다.
3-6. 산술적 좌측 / 우측 Shift 연산(Arithmetic Left / Right shift operations)
(1) 데이터를 부호 있는 정수로 간주하고, 부호 비트는 Shift하지 않습니다.
- 산술적 우측 Shift : 부호 비트가 그 우측에 있는 비트 위치에 복사됩니다.
- 산술적 좌측 Shift : 부호 비트는 그대로 두고, 나머지 비트들에 대해 논리적 좌측 Shift 연산을 수행합니다.
(2) 산술 연산 속도 증가
- 산술적 우측 Shift : 2로 나눈 것과 동일합니다.
- 산술적 좌측 Shift : 2를 곱한 것과 동일합니다.
- 산술적 좌측 Shift = 논리적 좌측 Shift : Overflow(오버플로우)가 발생하지 않는 경우는 동일합니다.
3-7. 좌측 / 우측 회전(Left / Right rotate : cyclic shift)
- 각 비트를 연속적으로 맨 좌측 비트로 옮기고, 부호 검사에 의해 그 비트의 값을 확인하는 경우에 사용됩니다.
3-8. 제어의 이동(Transfer of control)
(1) 분기(Branch)
- 무조건 분기와 조건 분기가 존재합니다.
(2) BRP X : 결과가 양수면, 위치 X로 분기합니다.
(3) BRN X : 결과가 음수면, 위치 X로 분기합니다.
(4) BRZ X : 결과가 0이면, 위치 X로 분기합니다.
(5) BRO X : 오버플로우가 발생하면 위치 X로 분기합니다.
(6) BRE R1, R2, X : R1 = R2이면 X번지로 분기합니다.
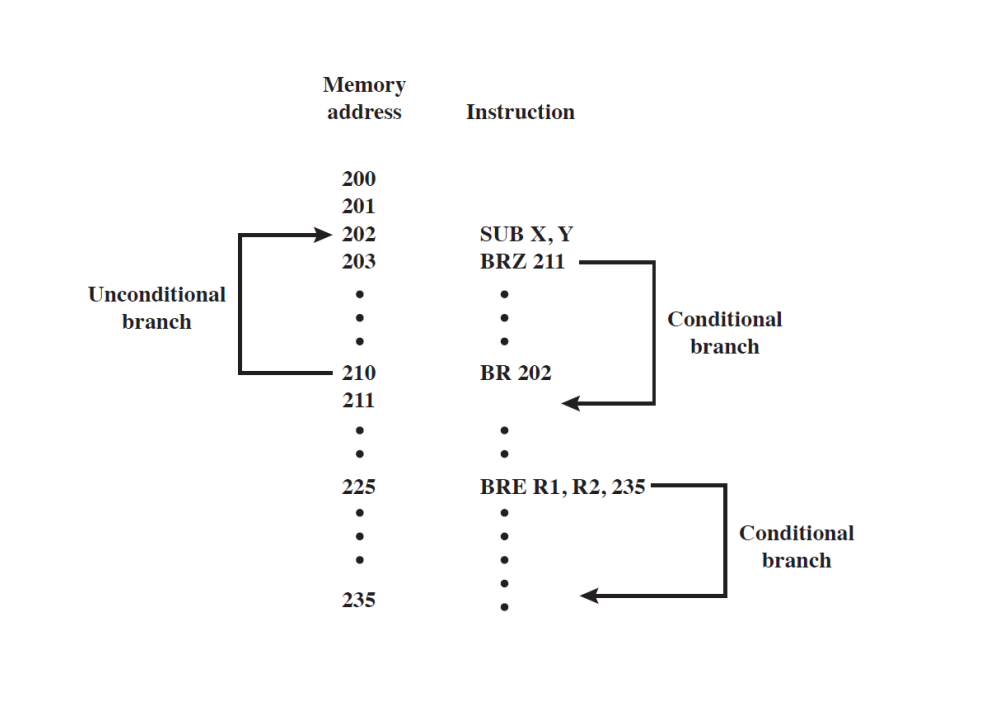
(7) Skip
- 한 명령어를 건너뛸 수 있습니다.
- 묵시적인 주소를 포함하여 이는 다음 명령어의 주소에 한 명령어의 길이를 더한 값입니다.
- Ex) increment and skip if zero(ISZ)

3-8. Subroutine call (서브루틴 호출)
(1) 프로시저(함수)를 사용하는 이유?
- 경제성 확보 : 코드의 재사용성을 보장할 수 있게 됩니다.
- 모듈화 진행 : 큰 프로그램을 작은 단위로 분할하여 관리 및 유지보수성을 증가시킵니다.
(2) 두 가지 기본적인 명령어
- 호출 명령어(Call instruction)
- 복귀 명령어(Return instruction)
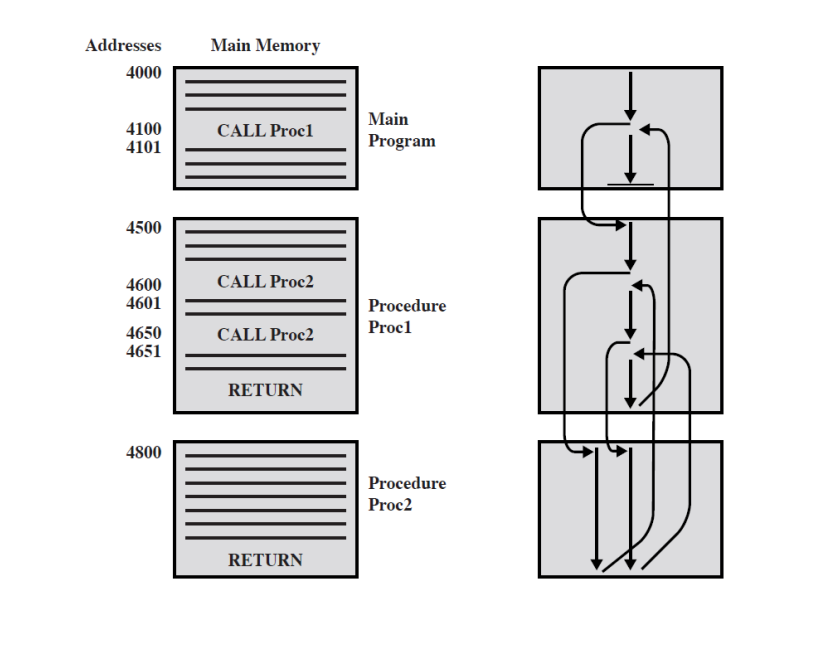
3-9. 복귀 주소

(3) 재귀 프로시저의 구현 예시 : n!을 구하는 함수
unsigned int caculateFactorial(unsigned int n) {
if (n <= 1) return 1;
else return n * caculateFactorial(n - 1);
}
(4) 스택(Stack)의 사용
- 호출(Call) : 복귀 주소를 저장합니다.(PUSH)
- 복귀(Return) : 스택의 최상위 복귀 주소를 사용합니다.(POP)
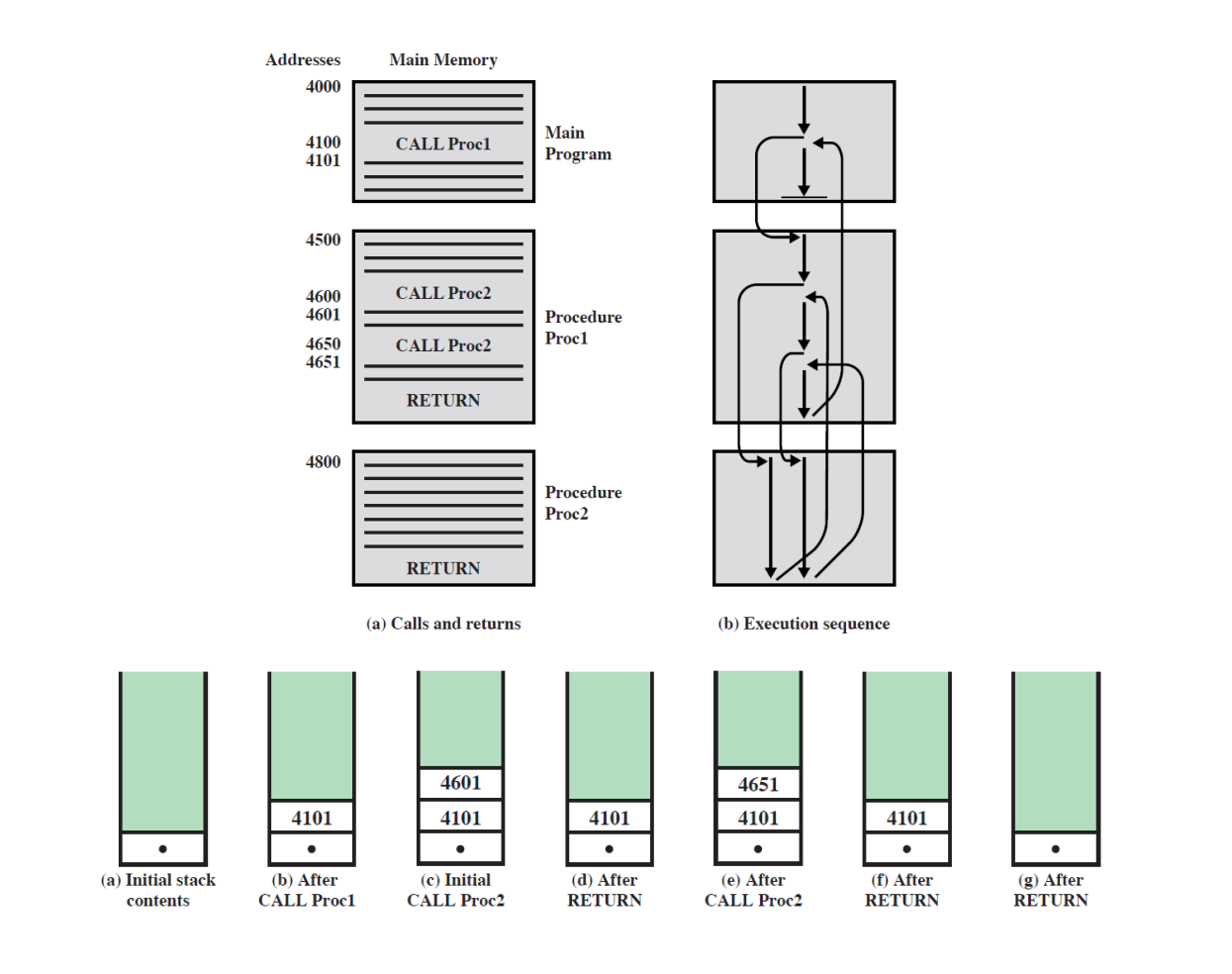
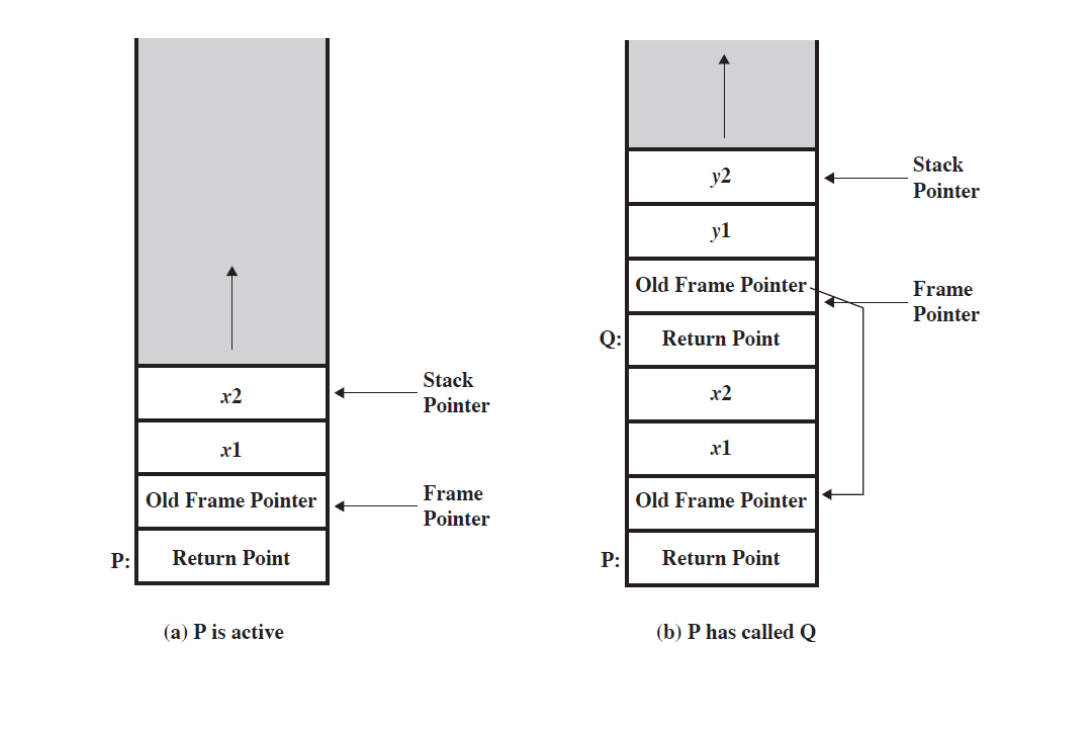
3-10. 스택 프레임(Stack frame)은 "복귀 주소 + 매개변수(인자, 지역 변수로 구성)" 구성
- 학부에서 수강했던 전공 수업 내용을 정리하는 포스팅입니다.
- 내용 중에서 오타 또는 잘못된 내용이 있을 시 지적해 주시기 바랍니다.
'전공 수업 > 컴퓨터 구조(Computer Architecture)' 카테고리의 다른 글
| [14주 차] - 기계 명령어 세트 : 주소 지정 방식과 형식 (0) | 2023.01.04 |
|---|---|
| [12주 차] - 컴퓨터 산술(Computer arithmetic) (2) | 2022.12.20 |
| [11주 차] - 프로그램 I/O, 인터럽트-구동 I/O, 직접 기억 장치 액세스(DMA) (0) | 2022.11.24 |
| [10주 차] - 외부 기억 장치 (2), I/O Module (0) | 2022.11.15 |
| [8주 차] - 내부 기억 장치 (2), 외부 기억 장치 (1) (0) | 2022.11.11 |




댓글