과목명 : 컴퓨터 구조(Computer Organization & Architecture)
수업일자 : 2022년 10월 06일 (목)
< Cache memory primary chapter list >
(A) 기억 장치 시스템의 특성
(B) 캐시 메모리(Cache memory)의 특성
(C) 캐시 사상(Cache mapping) 기법
- 동작 원리
- 직접 사상(Direct mapping)
- 연관 사상(Associative mapping)
- 세트 연관 사상(Set associative mapping)
- 캐시 교체 알고리즘(Cache replacement algorithm), 일관성 유지
1. 참조의 지역성(Locality of reference)
1-1. 참조 지역성(Locality of reference)의 정의
- 캐시 메모리의 크기는 주기억장치에 비하면 매우 작은 용량이고 컴퓨터의 성능 향상을 위해 프로세서가 원하는 데이터가 캐시 메모리에 적재될 수 있어야 하며 이에 따라 주기억장치에서 자주 사용되었거나, 재사용될 가능성이 높은 데이터를 효율적으로 가져와야 하고 이러한 특성을 메모리의 지역성(Locality)이라고 부릅니다.
- 참조의 지역성(Locality of reference)이란, 기억 장치 내의 정보를 균일하게 접근(Access)하는 것이 아닌 어느 한 순간에 특정 부분을 집중적으로 참조하는 특성입니다.
- 코드나 데이터 또는 이러한 값들을 가진 저장 공간(Storage space)의 위치가 프로세서에 의해 짧은 시간 내 재사용되는 특성을 의미합니다.
- 이러한 메모리의 지역성은 시간적 지역성(Temporal locality), 공간적 지역성(Spatial locality), 순차적 지역성(Sequential locality)으로 구분됩니다.
1-2. 시간적 지역성(Temporal locality)
- 시간적 지역성이란, 프로세서에 의해 최근에 엑세스되었던 기억 장치의 공간들을 이후에 다시 엑세스할 확률이 높다는 것을 의미합니다.
- 최근에 사용된 명령어들과 데이터 값들을 캐시 메모리에 적재하고 이후에 캐시 메모리를 통해 해당 명령 또는 데이터를 다시 불러옵니다.
- 시간적 지역성의 예시로는 반복 작업(Loop), 함수 호출(Function call) 등이 있습니다.
1-3. 공간적 지역성(Spatial locality)
- 공간적 지역성이란, 기억 장치 내부에 서로 인접하여 저장된 데이터들이 이후에도 다시 엑세스할 확률이 높다는 것을 의미합니다.
- 공간적 지역성의 대표적인 예시로 배열(Array)이 있습니다.
1-4. 순차적 지역성(Sequential locality)
- 순차적 지역성이란, 특정 조건이 존재하지 않는 한 데이터가 순차적으로 엑세스되는 경향을 의미하며 프로세스 내의 명령어가 순차적으로 구성되어 있다는 것이 대표적인 경우이고 공간적 지역성에 포함되어 설명되기도 합니다.
2. 평균 액세스 시간(Average access time)
2-1. 캐시 히트(Cache hit)
- 캐시 히트(Cache hit)는, 프로세서가 특정 데이터를 요청했을 때 해당 데이터가 캐시 메모리에 존재하는 것을 말합니다.
2-2. 캐시 미스(Cache miss)
- 캐시 미스(Cache miss)는, 프로세서가 특정 데이터를 요청했을 때 해당 데이터가 캐시 메모리에 존재하지 않아 메인 메모리에서 해당 데이터를 가져와야 하는 경우를 말합니다.
2-3. 평균 액세스 시간


- 캐시의 적중률(Hit rate)가 높아질수록, 평균 기억장치의 액세스 시간은 캐시 메모리 액세스 접근 시간과 비슷해집니다.
3. 캐시 메모리(Cache memory)의 원리
3-1. 캐시 메모리(Cache memory)의 정의
- 캐시 메모리는 프로세서와 주기억장치에 존재하는 범용 메모리로써 프로세서와 주기억장치 간의 속도 차이로 발생하는 시스템의 * 병목 현상을 최소화하기 위한 장치입니다.
* 병목 현상(Bottleneck phenomenon) : 전체적인 시스템의 성능이 하나의 구성요소로 인해 제한을 받는 현상
* 캐싱(Caching) - 이전에 자주 참조되었던 데이터를 미리 복사해 두었다가 이후에도 빠르게 사용될 수 있도록 하는 기법을 의미하며 캐싱을 통한 사용자 경험(User experience)을 향상시키는 것에 주된 목적을 가지고 있습니다.
3-2. 다중 레벨의 캐시 사용
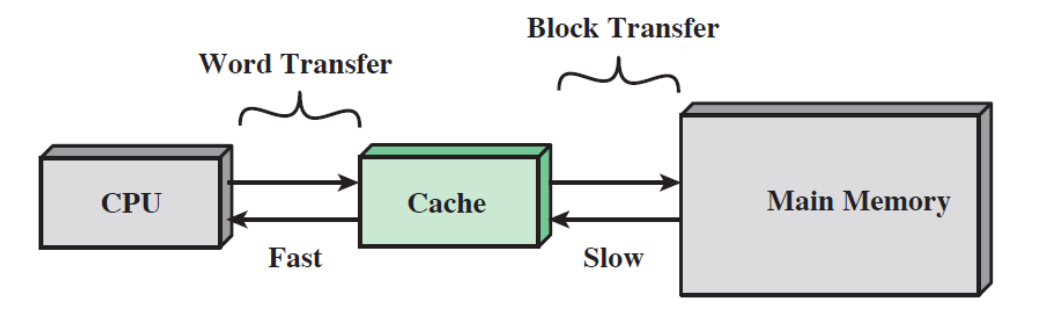
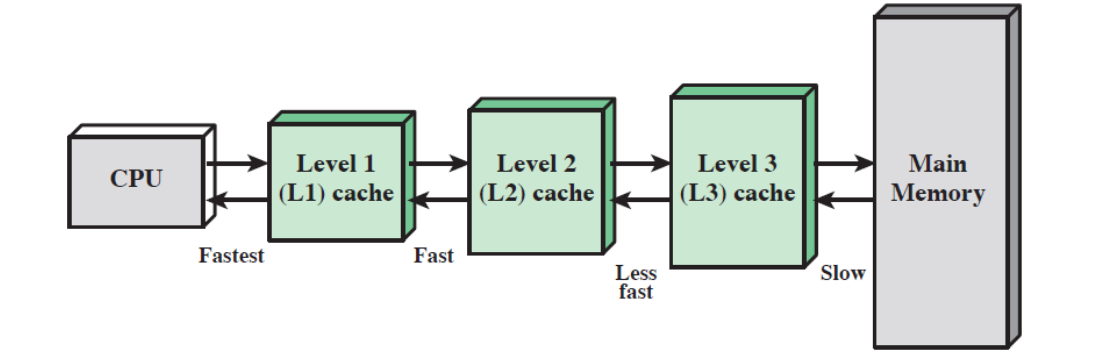
- L2 캐시는 L1 캐시보다 느리며 용량이 더 크고 이에 따라 L3 캐시도 L2 캐시보다 느리며 용량이 더 큽니다.
- 프로세서와 캐시는 워드(Word) 단위로 데이터를 주고받으며 캐시와 주기억장치는 Block 단위로 데이터를 주고받습니다.
3-3. 캐시 읽기 동작 과정

(1) Receive address RA from CPU
- CPU로부터 RA 주소를 받습니다
(2) Is block containing RA in cache?
- 캐시에 RA를 포함하는 블록이 존재하는지 검사합니다.
- Yes(Cache Hit)
(2-1) Fetch RA word and deliver to CPU
- RA에 있는 단어를 CPU로 전달합니다. (원하는 정보를 CPU에게 전송)
(2-2) DONE
- 읽기 동작 완료
- No(Cache Miss)
(3-1) Access main memory for block containing RA
- RA를 포함하고 있는 block을 가진 주기억장치에 접근합니다.
(3-2) Allocate cache line for main memory
- 정보 블록에 대한 캐시 라인을 할당합니다.
(3-3)
Load main memory block into cache line
- 주기억장치의 정보 블록을 캐시에 저장합니다.
Deliver RA word to CPU
- 요청한 정보를 CPU로 전달합니다
DONE
- 읽기 동작 완료
3-4. 전형적인 캐시 조직

- 캐시 메모리는 데이터, 제어 및 주소 선들을 통해 프로세서와 접속됩니다.
- 데이터 선, 주소 선들은 데이터 버퍼(Data buffer) 및 주소 버퍼(Address buffer)에도 연결됩니다.
해당 버퍼들은 시스템 버스(System bus)와 접속되어 주기억장치에 도달할 수 있게 해줍니다.
- 만약 Cache Hit가 발생하면 데이터 버퍼, 주소 버퍼는 차단되고 캐시와 프로세서만 통신하게 되며 정보를 주고받기 때문에 시스템 버스 트래픽은 발생하지 않게 됩니다.
- 만약 Cache Miss가 발생하면 CPU가 요청한 데이터의 주소가 시스템 버스에 실리고 이에 대한 데이터는 데이터 버퍼를 통해 들어와서 캐시와 프로세서로 동시에 전달됩니다. (이때, 데이터는 캐시로 이동될 때 Block 단위로, CPU로 이동될 때 Word 단위로 전송됩니다.)
- Cache Miss가 발생한 상황에선 원하는 단어가 캐시로 읽혀지고 이후에 읽혀진 데이터가 프로세서로 전달됩니다.
4. 캐시의 설계 요소
- 캐시를 설계할 때 아래의 요소들이 주요한 설계 요소에 해당됩니다.
| 1. Cache address (캐시 주소) |
| - Logiclal |
| - Physical |
| 2. Mapping function (사상 함수(기법)) |
| - Direct mapping |
| - Associative mapping |
| - Set associative mapping |
| 3. Cache replacement algorithm (캐시 교체 알고리즘) |
| - Least recently used(LRU) |
| - First in first out(FIFO) |
| - Least frequently used(LFU) |
| - Random |
| 4. Write policy (쓰기 정책) |
| - Write through |
| - Write back |
| 5. Line size ( = Block size) |
| 6. Number fo caches (캐시의 수) |
| - Single or two level |
| - Unified or split |
4-1. 캐시 주소(Cache address)
(1) 논리적 캐시(Logical cache)
- 가상 캐시(Virtual cache)라고 알려진 논리적 캐시는 가상 주소(Virtual address)를 이용하여 데이터를 저장합니다.
- * MMU(Memory management unit)를 거치지 않기 때문에 물리적 캐시보다 캐시 엑세스 속도가 빠릅니다.
* MMU(Memory management unit) : 논리 주소(가상 주소)를 물리 주소로 변환하는 장치
- 단점으로는 서로 다른 응용 프로세스에 동일한 가상 주소가 할당된 경우 데이터의 일치성이 깨질 수 있습니다.

(2) 물리적 캐시(Physical cache)
- 주기억장치의 물리적 주소를 사용하여 데이터를 저장합니다.

4-2. 캐시의 크기
- 캐시의 크기는 비트 당 평균 비용이 주기억장치의 평균 비용과 비슷해질 만큼 작아야 하고 전체적인 평균 엑세스 시간이 캐시의 엑세스 시간에 접근할 만큼 충분히 커야 합니다.
- 캐시의 크기를 최소화시켜야 합니다.
캐시의 용량이 커질수록 속도가 느려지는데, 캐시의 용량이 커질수록 캐시의 주소를 지정하기 위해 필요한 논리 게이트의 수가 많아지고 칩과 보드상의 공간에 의해서도 제약을 받기 때문입니다.
4-3. 사상 함수(기법) (Mapping function)
(1) 사상 함수의 정의와 특징
- 캐시의 라인(Line) 수는 주기억장치의 블록 수보다 적기 때문에 주기억장치 블록을 캐시의 라인으로 사상(Mapping)해 주는 알고리즘이 필요하고, 캐시 라인을 차지할 주기억장치 블록을 결정하는 수단이 필요하게 됩니다. 이에 따라 사상 함수(Mapping function)이 필요하며 사상 함수의 방식에 따라 캐시의 조직이 결정됩니다.
- 사상 함수는 직접 사상(Direct mapping), 연관 사상(Associative mapping), 세트 연관 사상(Set associative mapping)이 있습니다.
- 세 가지 사상 함수에 대해 아래와 같은 요소들이 적용됩니다.
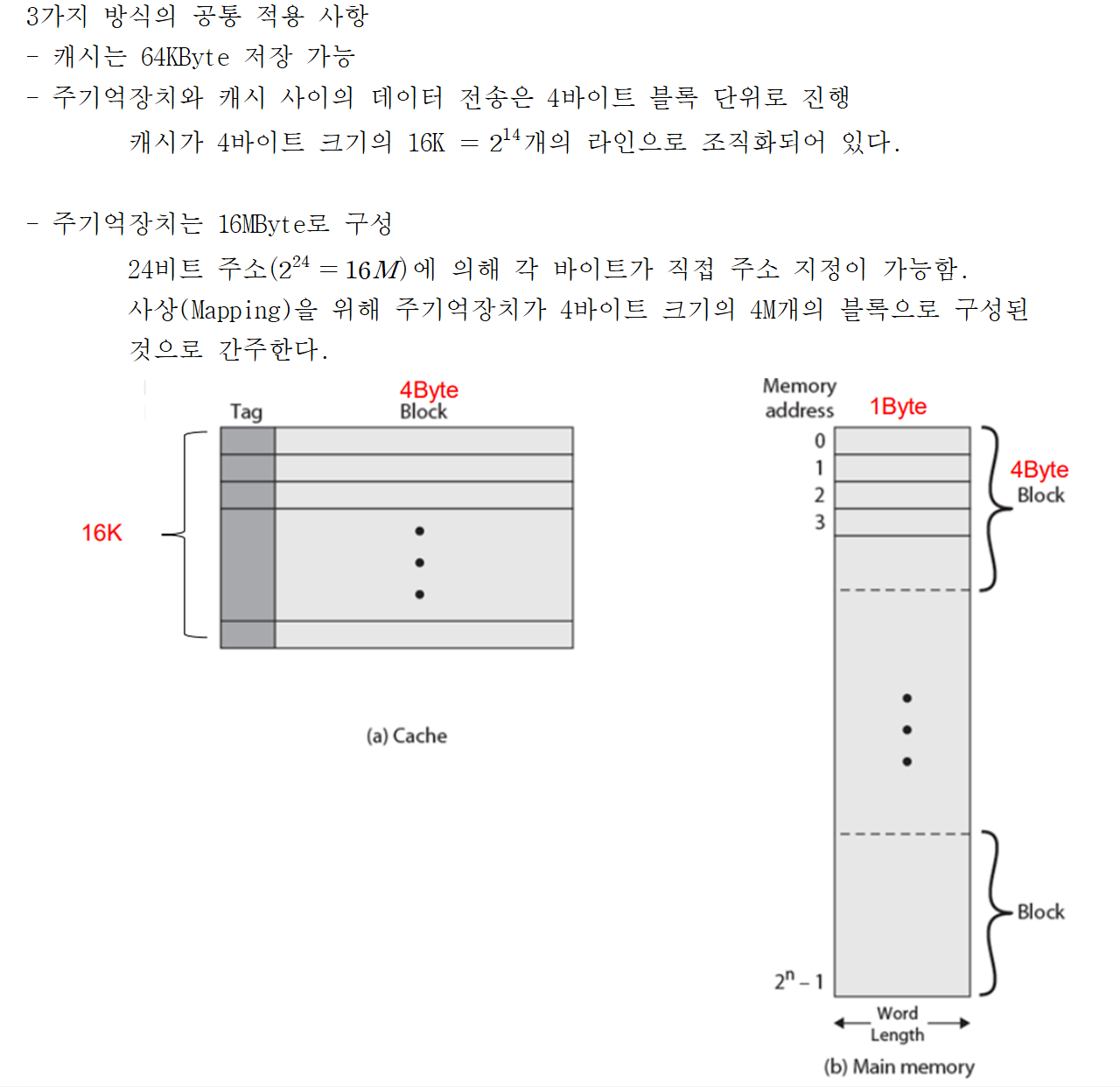
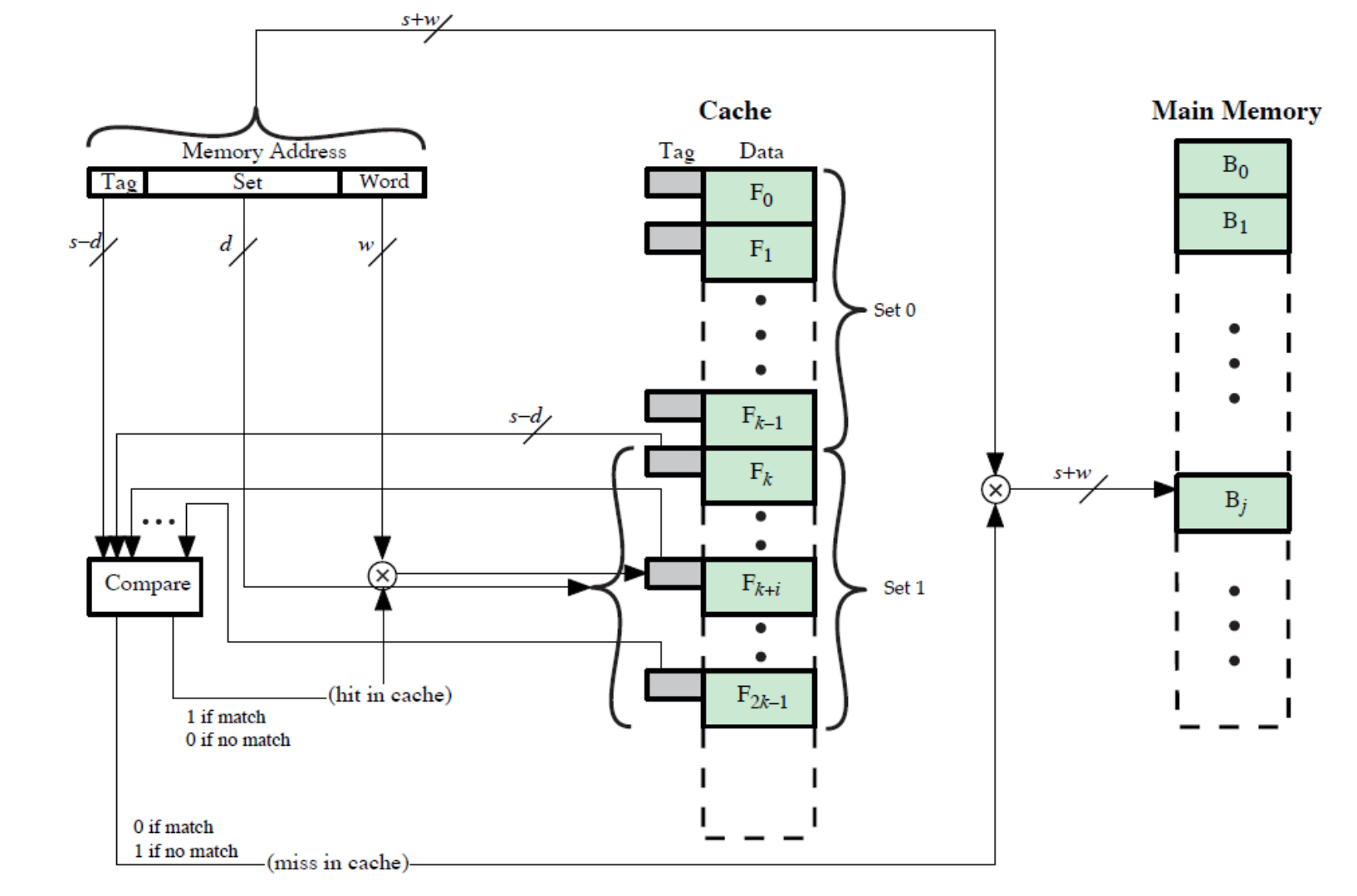
(2) 직접 사상(Direct mapping)
- 결과적으로 캐시의 각 슬롯에는 태그와 데이터 블록이 함께 저장되며 캐시 적중 여부는 주소의 기억장치의 주소 태그 비트들과 캐시 슬롯에 저장된 태그 비트들을 비교함으로써 결정됩니다.
- 주기억장치의 각 데이터 블록을 한 개의 캐시 라인으로만 사상하는 방식입니다.
- 직접 사상의 사상 함수는 다음과 같이 표현할 수 있습니다.


(2-a) 직접 사상의 결과 주기억장치 블록들은 다음과 같은 캐시 라인에 지정됩니다.
| 캐시 라인(Cache line) | Main memory blocks held |
| 0 | 0, m, 2m, 3m, ... , 2s-m |
| 1 | 1, m+1, 2m+1, ... , 2s-m+1 |
| ... | ... |
| m-1 | m-1, 2m-1, 3m-1, ... , 2s-1 |
(2-b) 직접 사상 방식의 주기억장치 주소 구성


(2-c) 직접 사상 방식의 캐시 조직

(2-d) 직접 사상 방식의 예시

(2-e) 직접 사상 방식의 장점과 단점
- 장점 : 방식이 간단하고 구현 비용이 적게 듭니다.
- 단점 : 특정한 데이터 블록이 들어갈 수 있는 캐시 위치가 고정되어 있어 적중률(Hit rate)이 떨어집니다.
(3) 연관 사상(Associative mapping)
- 연관 사상 방식은, 주기억장치 블록이 캐시의 어떤 라인으로도 적재될 수 있는 사상 기법입니다.
- 캐시의 어떤 라인으로도 적재될 수 있도록 허용함으로써 직접 사상 방식의 단점을 극복하고 있습니다.
- 태그 필드만으로 주기억장치 데이터 블록의 필드를 구분합니다.
- 프로세서가 요구하는 데이터 블록이 캐시에 있는지 확인하기 위해서 태그가 일치하는지 모든 캐시 라인과 비교가 필요합니다.

(3-a) 연관 사상 방식의 주기억장치 주소 구성


(3-b) 완전 연관 사상 방식의 캐시 조직

(3-c) 연관 사상 방식의 예시

(3-d) 연관 사상 방식의 장점과 단점
- 장점 : 새로운 데이터 블록이 캐시로 읽혀질 때 블록에 교체하는데 있어서 융통성이 존재합니다.
- 단점 : 캐시 라인들의 태그들을 병렬로 검사하기 위한 복잡한 회로가 필요합니다.
(4) 세트(집합) 연관 사상(Set associative mapping)
- 세트 연관 사상은, 직접 사상과 연관 사상의 장점을 취하고 단점을 최소화하기 위한 사상 기법입니다.
- 이 경우에 캐시는 여러 세트들로 나누어지며 각 세트들은 여러 개의 라인으로 구성됩니다.
세트 연관 사상의 관계식은 아래와 같습니다.

(4-a) v 연관 - 사상 캐시
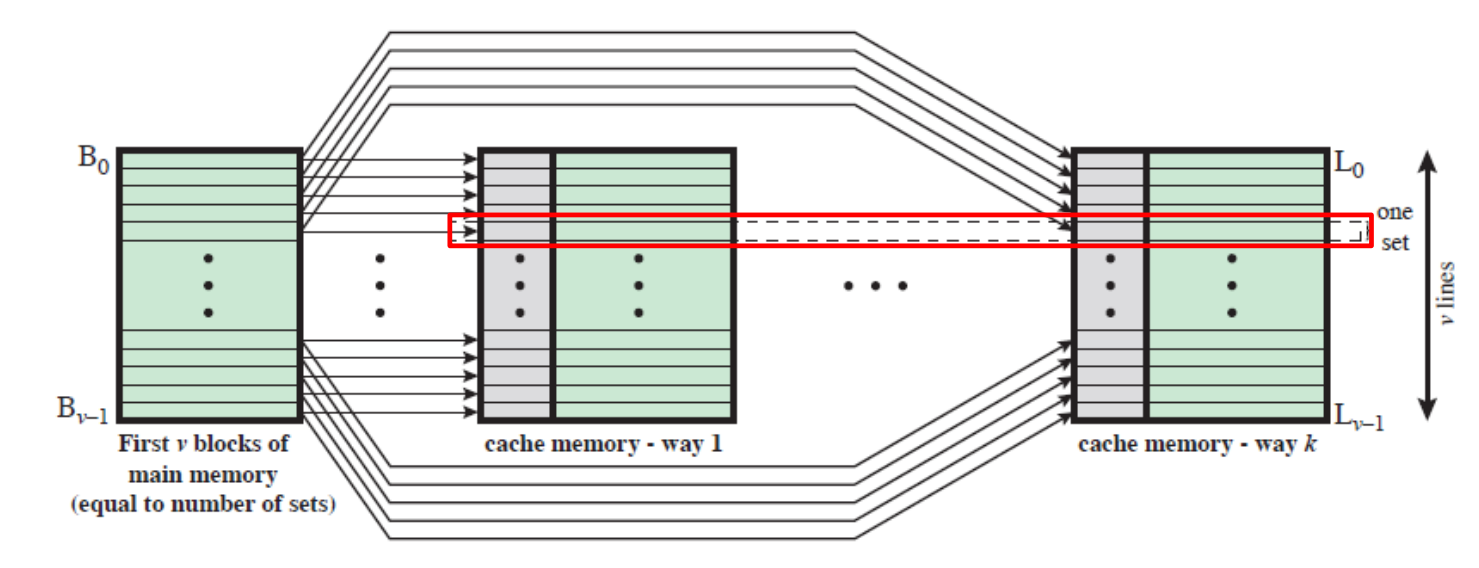
- 세트 연관 캐시는 물리적으로 v개의 연관 캐시들로 구현이 가능합니다.
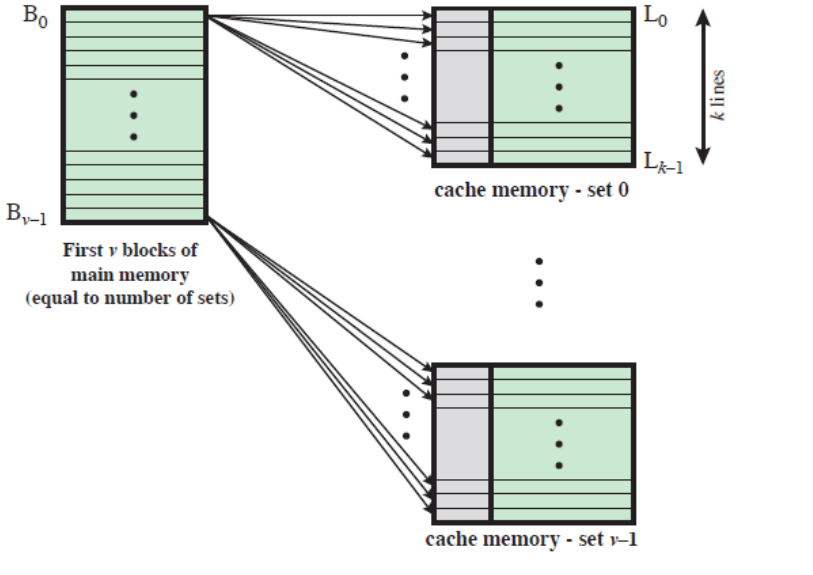
(4-b) k 직접 - 사상 캐시
- 세트 연관 캐시는 k개의 직접 사상 캐시들로 구현이 가능합니다.
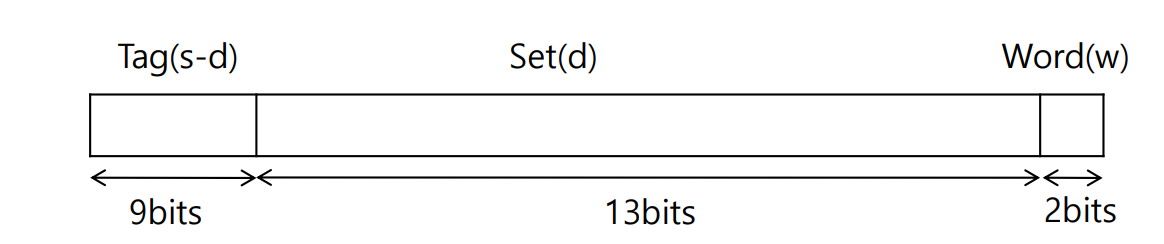
(4-c) 세트 연관 사상의 주기억장치 주소 형식

(4-d) k way 세트 - 연관 캐시 조직
(4-e) 2-way 세트 - 연관 사상의 예시

4-4. 캐시 크기에 대한 여러 가지 연관성
- 아래의 그래프는 세트-연관 캐시의 성능을 캐시 크기의 함수로써 시뮬레이션한 연구 결과를 보여주고 있습니다.
해당 시뮬레이션은 아래와 같은 결론을 갖게 됩니다.

- 직접 사상과 2-way 세트-연관 사상 간의 성능 차이는 캐시 크기가 적어도 64 KB가 될 때까지는 상당히 큰 편입니다.
- 캐시의 복잡도는 연관성(Associativity)에 비례하여 증가합니다.
- 캐시의 크기가 32 KB 이상 되더라도 성능은 크게 증가하지 않습니다.
- 학부에서 수강했던 전공 수업 내용을 정리하는 포스팅입니다.
- 내용 중에서 오타 또는 잘못된 내용이 있을 시 지적해 주시기 바랍니다.
'전공 수업 > 컴퓨터 구조(Computer Architecture)' 카테고리의 다른 글
| [8주 차] - 내부 기억 장치 (2), 외부 기억 장치 (1) (0) | 2022.11.11 |
|---|---|
| [7주 차] - 캐시(Cache) 메모리 (2), 내부 기억 장치 (1) (0) | 2022.10.31 |
| [5주 차] - 컴퓨터의 기능과 상호 연결 (2), 기억 장치 시스템의 특성 (0) | 2022.10.02 |
| [4주 차] - 컴퓨터 시스템의 성능 (2), 컴퓨터의 기능과 상호 연결 (1) (4) | 2022.09.25 |
| [3주 차] - 컴퓨터 시스템의 성능 (1) (0) | 2022.09.19 |




댓글