과목명 : 컴퓨터 구조(Computer Organization & Architecture)
수업일자 : 2022년 10월 13일 (목)
< Cache memory primary chapter list >
(A) 기억 장치 시스템의 특성
(B) 캐시 메모리(Cache memory)의 특성
(C) 캐시 사상(Cache mapping) 기법
- 동작 원리
- 직접 사상(Direct mapping)
- 연관 사상(Associative mapping)
- 세트 연관 사상(Set associative mapping)
- 캐시 교체 알고리즘(Cache replacement algorithm), 일관성 유지
1. 캐시 교체 알고리즘(Cache replacement algorithm)
1-1. 정의와 특징
- 캐시에 모든 데이터를 다 담을 수 없기 때문에 메모리의 데이터 블록을 캐시로 가져올 때는 현재 캐시에 저장되어 있는 데이터 블록을 내려야 하고 어떤 데이터 블록을 내릴 것인지에 대해 결정하는 것을 캐시 교체 알고리즘(Cache replacement algorithm)이라고 합니다.
- 직접 사상(Direct mapping)의 경우 임의의 블록이 들어갈 수 있는 라인이 하나 뿐이라 교체 알고리즘과 연관이 없지만, 연관 사상(Associative mapping), 세트 연관 사상(Set associative mapping) 기법에서는 교체 알고리즘이 필요합니다.
- 일반적으로 사용되는 네 가지 알고리즘에 대해 알아보겠습니다.
1-2. 선입선출(First In First Out, FIFO)
- 캐시 내부에서 가장 오래 머물렀던 데이터 블록을 교체하는 것을 말합니다.
- FIFO 알고리즘은 라운드-로빈(Round-robin)이나 원형 버퍼 기법으로 구현될 수 있습니다.
1-3. 최소 사용 빈도(Least Frequently Used, LFU)
- 캐시 내부에서 가장 적게 참조되었던 데이터 블록을 교체하는 것을 말합니다.
- LFU 알고리즘은 각 라인에 카운터(Counter)를 배치함으로써 구현될 수 있습니다.
1-4. 최소 최근 사용(Least Recently Used, LRU)
- 캐시 내부에서 참조되지 않은 채로 가장 오래 머물렀던 블록을 교체하며, 결과적으로 마지막 참조 시점이 가장 오래되었던 데이터 블록을 교체하게 됩니다.
- FIFO, LFU 알고리즘을 모두 고려한 방식이 바로 해당 LRU 알고리즘입니다.
- 지금까지 소개된 교체 알고리즘 중에서 적중률이 가장 높고, 가장 널리 사용되는 기법입니다.
1-5. 임의(Random)
- 참조되었던 시간, 참조 횟수를 근거하지 않고 교체 후보 라인 중에서 한 라인을 임의로 선택하여 교체하는 기법을 말합니다.
- 참조 횟수에 근거한 위의 알고리즘보다 성능이 약간 떨어진다는 특징이 있습니다.
2. 쓰기 정책(Write policy), 캐시 일관성(Coherency) 유지
2-1. 개요
- 캐시에 적재되어 있던 데이터 블록이 교체될 경우 기존 데이터 블록의 값에 변화가 없다면 상관없지만 만약 프로세서의 쓰기(Write) 작업 및 연산으로 블록의 값이 변경된 경우, 변경된 내용을 주기억장치의 데이터 블록에 대한 값도 갱신(일치)시켜 주어야 합니다.
2-2. 쓰기 정책(Write policy)의 뜻과 두 가지 기법
- 이러한 데이터 블록의 쓰기 정책(Write policy)이란, 캐시 라인의 데이터 내용과 주기억장치의 데이터 블록의 값을 갱신(일치)시켜주는 기법을 의미하며, 아래와 같이 두 가지 기법이 존재합니다.
(1) Write-through(즉시 쓰기) 기법

- 프로세서에 의한 모든 쓰기 동작들이 캐시뿐만 아니라 주기억장치에서도 동시에 행함으로써 주기억장치의 내용들은 항상 유효하도록 보장하는 기법입니다.
- 다른 프로세서-캐시 모듈은 자신의 캐시의 일관성(Consistency)을 위해 주기억장치와의 트래픽을 모니터링합니다.
- 단점으로는, 기억 장치 사용량이 급증하여 병목 현상을 야기할 수도 있습니다.
(2) Write back(나중에 쓰기) 기법
- 기억 장치에 대한 쓰기 동작을 최소화하는 기법으로, 데이터의 갱신이 캐시에서만 일어납니다.
- 갱신 동작이 일어날 때 Dirty bit 또는 Use bit를 사용하여 해당 데이터 블록이 교체될 때 Dirty Bit 또는 Use bit가 1로 세트된 블록에 대해서만 주기억장치의 데이터 블록 값이 갱신됩니다.
- 단점으로는, 주기억장치의 일부분이 무효(Invalid) 상태가 될 수 있으며 I/O 모듈에 의한 엑세스는 캐시를 통해서 이루어져야 합니다.
2-3. 캐시 일관성(Coherency) 유지
(1) 정의
- 두 개 이상의 프로세서들이 각자의 캐시를 통해 주기억장치를 공유하는 구조에서, 만약 캐시 내의 데이터 값이 변경된다면 주기억장치 내의 해당 데이터 뿐만이 아니라 다른 캐시 내에 있는 해당 데이터도 무효(Invalid)가 되는 문제를 가지게 됩니다. 이러한 문제를 해결하는 것을 캐시 일관성(Coherency) 유지라고 합니다.
- 일관성을 유지하기 위해 아래와 같은 세 가지 기법이 존재합니다.
(2) Write-through를 이용한 버스 감시
- 각 캐시 제어기는 다른 버스 마스터가 기억 장치에 쓰기(Write)를 하면, 이것을 감지하여 쓰기가 된 주소를 모니터링합니다.
- 만약 다른 기억 장치에 쓰고 있는 데이터가 자신의 캐시에도 존재한다면 캐시 제어기는 캐시 내의 해당 데이터를 무효화시킵니다.
- 모든 캐시 제어기들이 Write-through 기법을 이용하는 경우에만 해당 방식이 사용됩니다.
(3) 하드웨어 투명성(Hardware transparency)
- 주기억장치에 대한 모든 갱신들이 다른 모든 캐시들에 반영되도록 별도의 하드웨어를 추가하는 기법입니다.
(4) 캐시 불가능 기억 장치(Noncacheable memory)
- 주기억장치의 일부분만 한 개 이상의 프로세서들에 의해 공유되도록 하며 해당 일부분의 데이터는 캐시에 적재될 수 없게 하는 기법입니다.
3. 라인 크기(Line size)
- 한 개의 데이터 블록이 캐시에 저장될 때, 프로세서가 원하는 단어(Word) 뿐만이 아닌 그 주위에 인접한 몇 개의 단어들도 같이 저장됩니다.
(1) 블록의 크기 증가
- 지역성의 원리에 의해 초반엔 캐시의 적중률(Hit rate)이 증가합니다.
- 그러나 블록이 계속 커진다면 필요하지 않은 데이터 블록도 같이 가져올 수 있게 되므로 적중률이 감소하게 됩니다.
(2) 블록 크기와 캐시 적중률의 관계
- 블록이 커질수록 캐시에 들어올 수 있는 블록의 수는 감소합니다.
- 블록이 커질수록 원하는 단어로부터 멀리 떨어진 단어들도 같이 읽혀오며 해당 단어들이 미래에 참조될 가능성은 낮습니다.
(3) 대략적으로 8~64 바이트의 크기가 최적의 캐시 라인 크기로 알려져 있습니다
4. 캐시의 수
4-1. 개요
- 최근에는 다수의 캐시를 사용하는 것이 보편적인 방법이 되고 있습니다.
- 이에 따라 캐시 설계 시 캐시의 단계(Level) 설정과 통합(Unified) 또는 분리(Split) 캐시를 사용할지 총 두 가지의 주요 결정 사항들을 고려해야만 합니다.
4-2. 다단계 캐시(Multi-level caches)
- 다단계 캐시를 사용하여 성능을 향상시킬 수는 있지만, 캐시 설계와 관련된 라인 크기, 교체 알고리즘, 쓰기 정책 등이 더 고도화되고 있습니다.
- 캐시를 프로세서 내부에 배치하는 것을 온 칩(On-chip) 캐시라고 합니다.
프로세서의 외부 활동을 줄여주어 실행 시간을 가속시키고 전체 시스템의 성능을 향상시키게 됩니다.
- 대부분의 현 시점의 컴퓨터들은 온 칩 캐시(On-chip cache)와 외부 캐시(External) 캐시를 모두 가지고 있습니다.
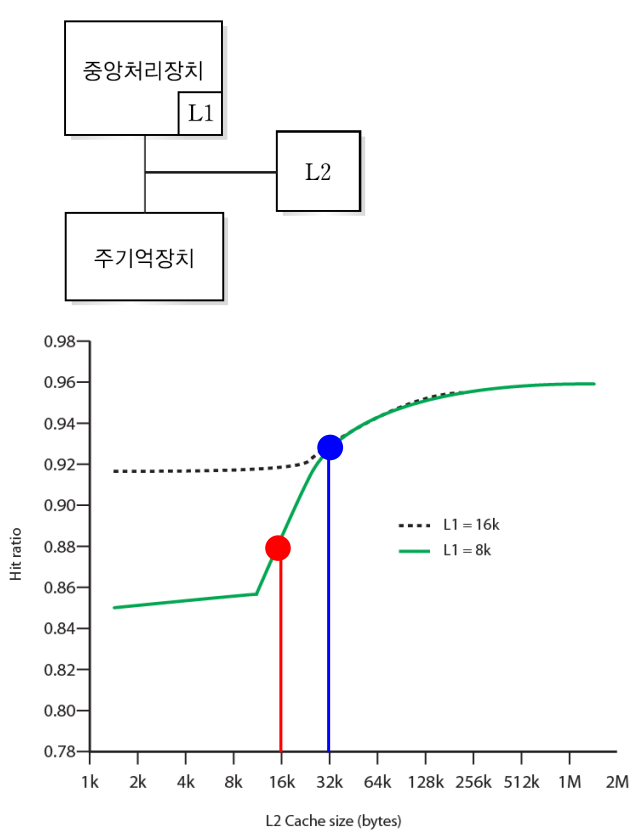
- 해당 그래프는 L1 캐시의 크기에 대해 L2가 전체 캐시 적중에 미치는 영향을 보여줍니다.
- L2 캐시는 L1 캐시 용량의 두 배가 되기 전까지는 캐시 적중률에 큰 영향을 주지 않습니다.
- 그러나 L1 캐시들의 각 용량 8 KB, 16 KB에 대하여 L2의 캐시 용량이 16 KB, 32 KB가 되는 순간 적중률이 극대화됩니다.
4-3. 분리 캐시(Split cache), 통합 캐시(Unified cache)
(1) 분리 캐시(Split cache)
- 같은 레벨의 캐시에서, 명령어 전용 캐시와 데이터 전용 캐시로 캐시의 영역을 구분하는 것을 말합니다.
- 명령어 파이프라인에 의존하는 설계에선 명령어 인출/해독 유니트와 실행 유니트 간에 캐시로 인한 경합을 없앨 수 있기 때문에 중요한 요소가 됩니다.
(2) 통합 캐시(Unified cache)
- 같은 레벨의 캐시에서 한 캐시에 데이터와 명령어를 모두 저장하는 것을 말합니다.
- 통합 캐시는 명령어와 데이터 간의 균형을 자동으로 유지하여 분리 캐시보다 캐시 적중률이 더 높습니다.
- 단 한 개의 캐시만 설계하고 구현해야 한다는 장점이 있습니다.
< 내부 기억 장치(Internal memory) chapter list >
(A) 반도체 기억장치(Semiconductor main memory)
(B) 오류 정정
(C) 향상된 DRAM의 조직
- SDRAM
- DDR SDRAM
- DDR2
- DDR3
5. 반도체 기억장치(Semiconductor memory)
5-1. 정의
- 내부 기억 장치는 흔히 알고 있는 메모리로써 프로세서와 직접적으로 통신이 가능한 메모리를 의미합니다. 반대로 외부 기억 장치는 CD-ROM, HDD와 같은 보조 기억을 담당하는 보조 기억 장치이며 프로세서와 직접적으로 통신할 수 없습니다.
- 반도체 기억장치는 반도체 칩으로 설계된 주기억장치를 뜻하며 현대의 컴퓨터들은 반도체를 이용해 다수의 기억장치를 구성하고 있으며 흔히 언급되는 CPU 레지스터, 캐시 메모리, 주기억장치(RAM), SSD 등이 이와 같은 반도체 기억 장치입니다.
5-2. 반도체 기억 장치의 기본 요소
(1) 반도체 기억 장치의 기본 요소는 기억 소자(Memory cell)이며 다음과 같은 성질을 가집니다.
- 두 개의 안정된 상태로 2진수 타입의 값 1 또는 0을 갖습니다.
- 상태를 세트할 수 있도록 적어도 한 번은 쓰여질 수 있습니다.
- 상태를 감지할 수 있도록 읽혀질 수 있습니다.
(2) 기억 소자(Memory cell)의 동작
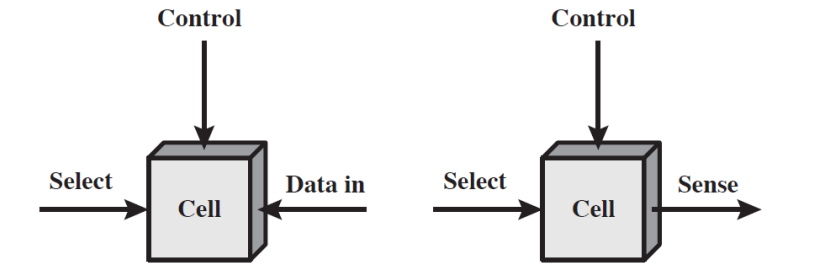
- 선택 단자(Select) : 읽기 또는 쓰기 동작을 할 기억 소자를 선택할 때 사용됩니다.(기억 소자의 주소가 결정된 경우)
- 제어 단자(Control) : 읽기 또는 쓰기 동작을 지정합니다.
- Data in : 쓰기 동작의 경우, 기억 소자의 상태를 1 또는 0으로 세트할 전기 신호가 들어오는 통로입니다.
- Sense : 기억 소자의 상태를 출력할 때 사용됩니다.
(3) 반도체 기억장치의 유형
| Memory type | Category | Erasure | Write mechanism | Volatility |
| Random Access Memory (RAM) | Read-Write | Electrically, byte-level | Electrically | Volatile |
| Read-only Memory (ROM) |
Read-only | Not-possible | Masks | Non-volatile |
| Programmable ROM (PROM) |
Electrically | |||
| Erasable PROM (EPROM) |
Read-mostly memory |
UV Light, chip-level | ||
| Electrically Erasable PROM(EEPROM) |
Electrically, byte-level | |||
| Flash memory | Electrically, block-level |
5-4. DRAM(Dynamic RAM)
- 커패시터에 전하를 충전하는 방식으로 데이터를 저장하는 기억소자로 구성됩니다.
- 데이터의 저장 상태를 유지하기 위해 주기적으로 재충전(Refresh)이 필요합니다.
여기서 DRAM에서의 "Dynamic"은 전하가 누설(Leak away)되는 성질을 의미합니다.(이를 위한 별도의 회로 필요)
- 아날로그 장치
커패시터는 일정 범위 내의 어떤 전하값도 저장이 가능합니다.(기준값으로 1과 0을 구분)
- 가격이 저렴하고 대용량 기억장치를 구성할 수 있습니다.(주기억장치에 사용된다.)
동적 기억소자가 정적 기억소자보다 더 간단하고 작습니다.
- 주소 선은 이 소자로부터 비트값이 읽혀지거나 쓰여질 때 활성화됩니다.
(트랜지스터는 전압이 주소 선에 가해졌는지의 여부에 따라 스위치의 형태로 동작합니다.)
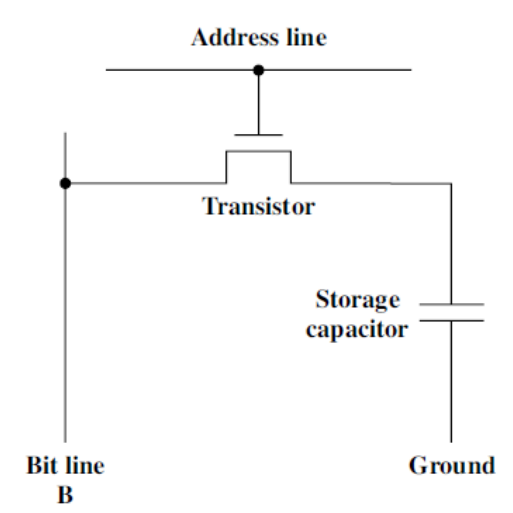
(1) DRAM의 동작 방식
(a) Write 동작
- 전압이 비트 선에 가해집니다. (High = 1, Low = 0)
- 주소 선으로 신호가 들어오면 그때 전하가 커패시터로 이동합니다.
(b) Read 동작
- 주소 선이 선택되면 트랜지스터가 켜집니다.
- 커패시터에 저장된 전하가 비트 라인을 통해 감지 증폭기로 보내집니다.(감지증폭기가 커패시터의 전압으로부터 1, 0을 결정)
- 읽기 동작 후 전하를 복원해야 합니다.
5-5. SRAM(Static RAM)
- 플립-플롭(Flip-flop) 논리 게이트를 이용하여 데이터를 저장하는 기억소자로 구성됩니다.
- 데이터를 유지하기 위해 재충전은 필요하지 않습니다. (전력이 공급되는 동안 데이터를 상시 유지)
- 비트 당 크기가 크고 복잡한 형태를 띄며, 캐시 메모리에 사용됩니다.
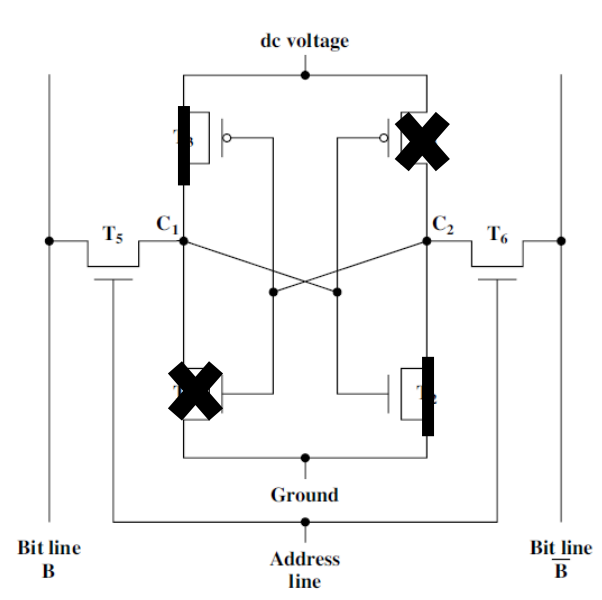


5-6. DRAM과 SRAM의 비교
- 모두 휘발성 기억소자입니다. (비트 값을 유지하기 위해 전력 공급이 지속적으로 이루어져야 합니다.)
- DRAM
(1) 더 간단한 형태의 회로이고 크기가 더 작습니다.
(2) 밀도가 높습니다. (단위 면적 당 소자의 수가 더 많다.)
(3) 가격이 저렴합니다.
(4) 재충전 회로가 필요합니다.
(5) 대용량 기억 장치에 주로 사용됩니다. (용량이 커질수록 재충전 회로 비용 비중이 낮아진다.)
- SRAM
(1) DRAM보다 더 빠른 속도를 가집니다.
(2) 캐시 메모리에 사용됩니다.
6. ROM(Read Only Memory)
6-1. 주요 특징
(1) 비휘발성 (Non-volatile) - 데이터를 기억장치에 저장하기 위한 전원 장치가 필요하지 않습니다.
(2) 쓰기 동작이 불가능합니다.
6-2. 응용되는 곳
- 빈번히 사용되는 라이브러리 서브루틴
- 시스템 프로그램이나 함수표
6-3. 단점
- 데이터를 삽입하는 과정에서 비교적 높은 비용이 발생합니다.
- 하나의 비트라도 문제가 생긴다면 모든 ROM을 버려야 합니다.
6-4. PROM(Programmable ROM)
- 사용자가 임의로 데이터를 쓸 수 있으나 1회성에 한하며 특수한 장치가 필요합니다.
- 데이터를 저장할 ROM의 수가 적을 때 가격이 저렴합니다.
6-5. EPROM(Erasable PROM)
- 자외선을 이용하여 모든 소자를 초기화시킵니다.
- 여러 번 지우고 쓰는 것이 가능하나 PROM보다 높은 가격을 요구합니다.
6-6. EEPROM(Electrically EPROM)
- 데이터를 쓰기 전에 이전 내용을 지울 필요가 없습니다.
- 주소가 지정된 한 바이트 또는 몇 바이트만 갱신 가능합니다.
- 일반적인 버스 제어, 주소 및 데이터 선을 이용하여 갱신 가능합니다.
- EPROM보다 가격이 더 비싸며 밀도가 낮습니다.
6-7. 플래시 메모리
- 기억 소자의 한 영역(블록 단위)이 한 동작만에 삭제 가능합니다.
- 바이트 단위로는 삭제할 수 없습니다.
- EPROM보다 훨씬 더 빠른 속도를 가지고 있습니다.
7. 칩 논리
- 기억 소자의 배열 : B개의 비트들로 이루어진 W개의 단어로 구성됩니다.
Ex) 16 MBit 칩 : 1M개의 16 Bit 단어로 구성
- 주소를 다중화하고 정방향 배열 구조를 사용하여 용량이 매 세대 당 4배수씩 증가했습니다.
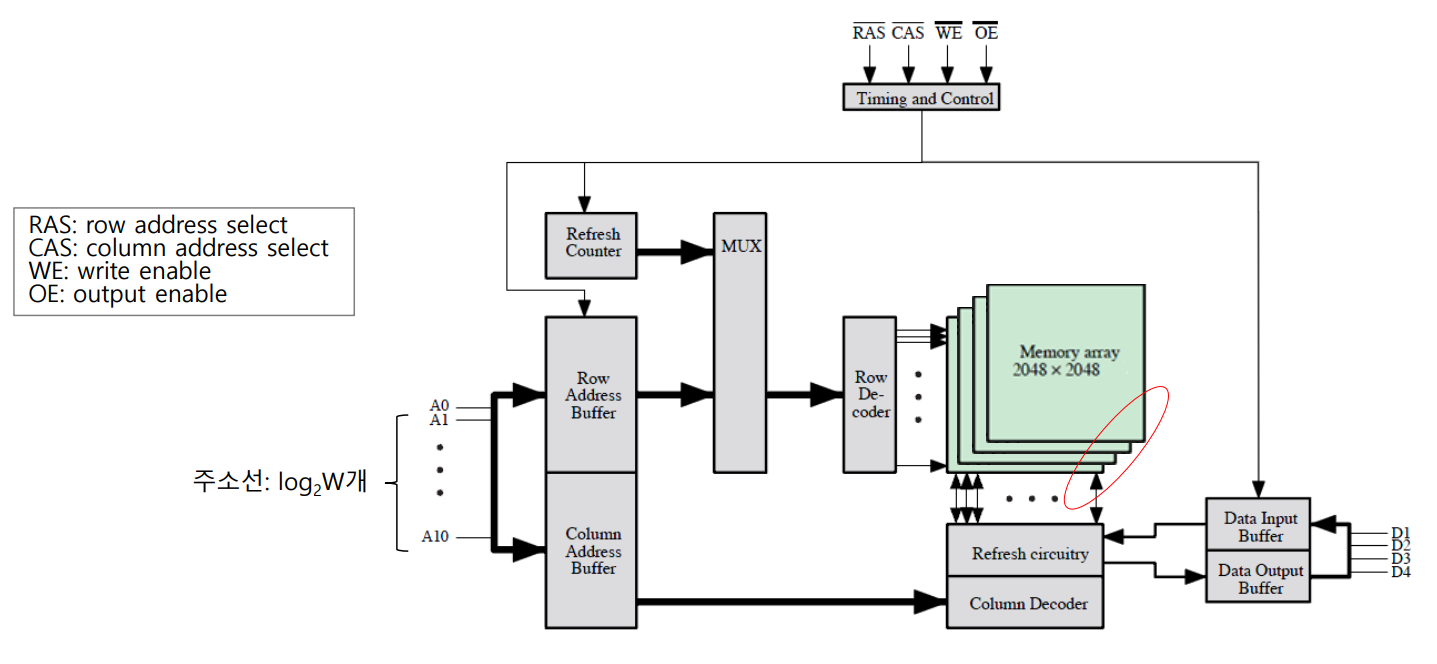
7-1. 칩 패키징
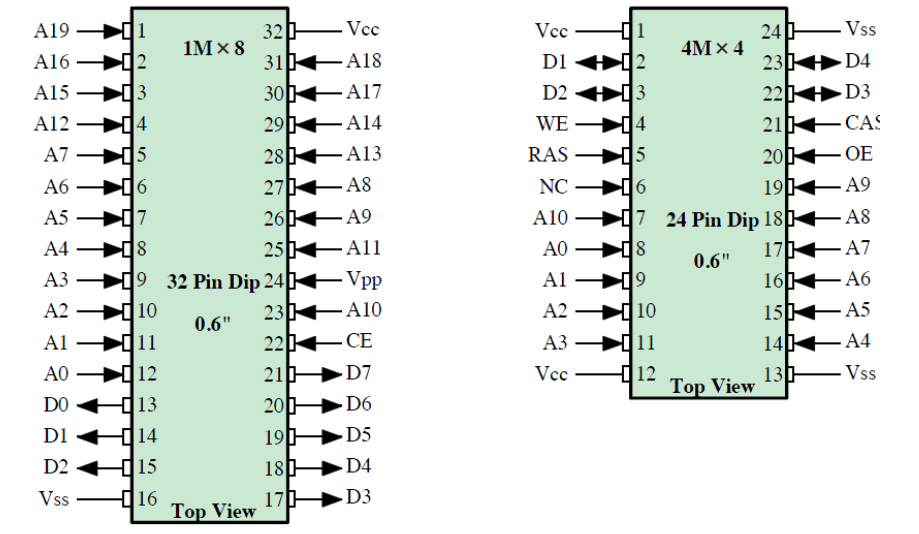
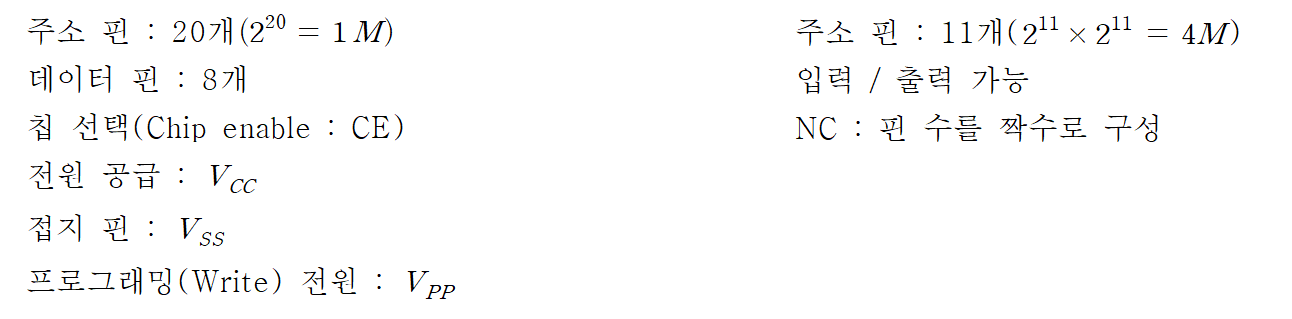
7-2. 기억 장치 모듈 조직
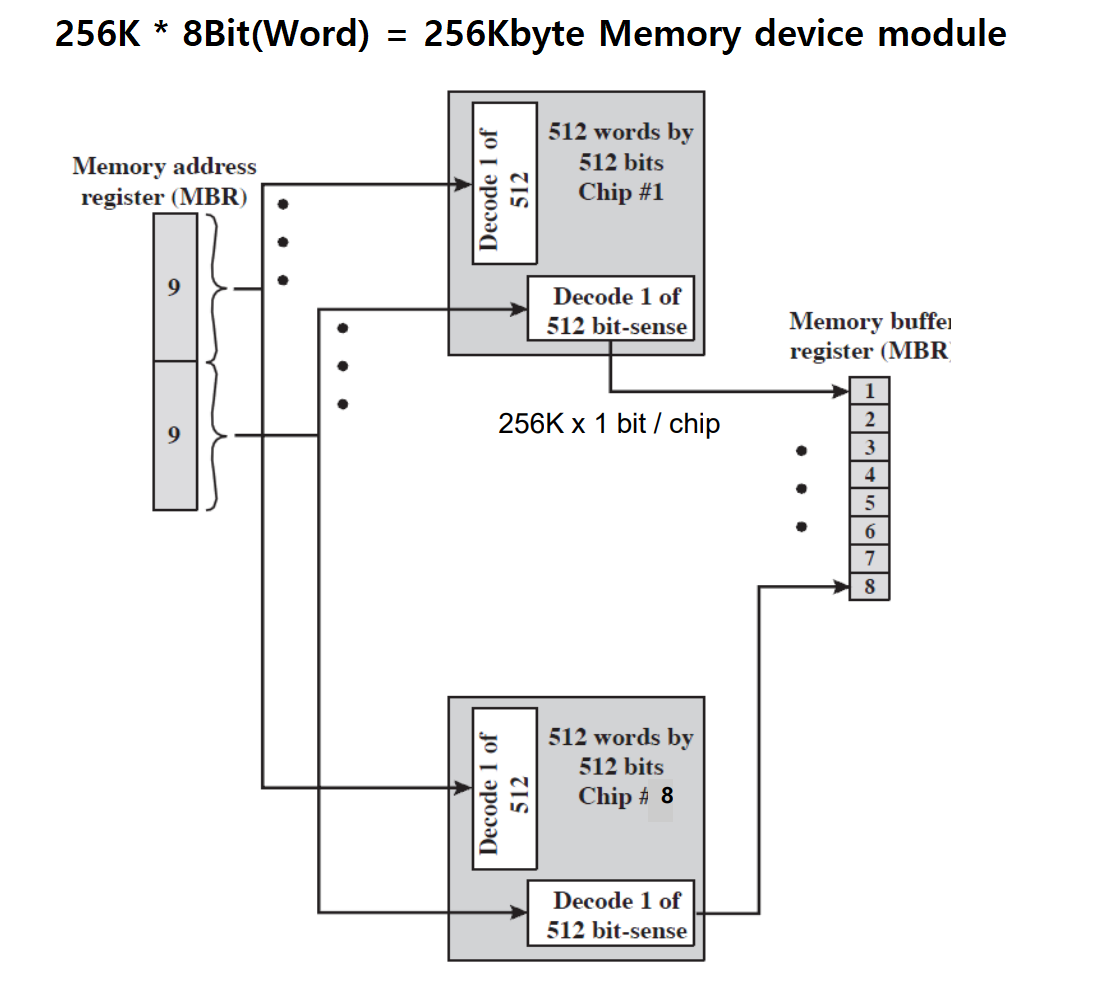
(1) 256 KByte 기억 장치 조직
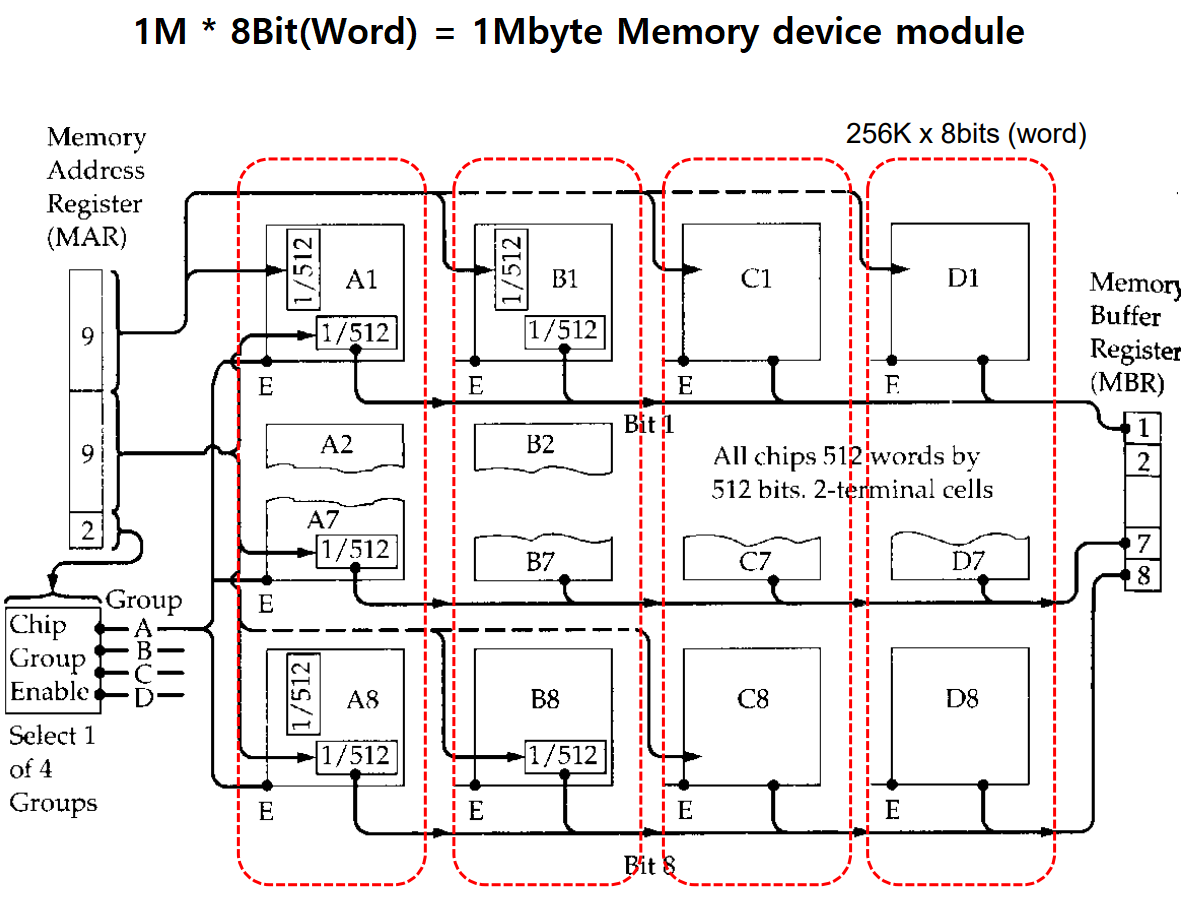
(2) 1 MByte 기억 장치 조직
- 학부에서 수강했던 전공 수업 내용을 정리하는 포스팅입니다.
- 내용 중에서 오타 또는 잘못된 내용이 있을 시 지적해 주시기 바랍니다.
'전공 수업 > 컴퓨터 구조(Computer Architecture)' 카테고리의 다른 글
| [10주 차] - 외부 기억 장치 (2), I/O Module (0) | 2022.11.15 |
|---|---|
| [8주 차] - 내부 기억 장치 (2), 외부 기억 장치 (1) (0) | 2022.11.11 |
| [6주 차] - 메모리(데이터) 참조 지역성, 캐시(Cache) 메모리 (1) (0) | 2022.10.18 |
| [5주 차] - 컴퓨터의 기능과 상호 연결 (2), 기억 장치 시스템의 특성 (0) | 2022.10.02 |
| [4주 차] - 컴퓨터 시스템의 성능 (2), 컴퓨터의 기능과 상호 연결 (1) (4) | 2022.09.25 |




댓글